Reputable factories will test 100% of every product shipped. For example, the computer or phone you’re using to read this has had a plug inserted in every connector, along with dozens of internal and external tests run to confirm everything from the correct operation of the CPU to the proper function of the buttons.
A test station at a motherboard factory (2x speed). Every port and connector gets tested.
Even highly automated processes can yield defective units: entropy happens, and constant vigilance is required to guard against it. Even a very stable manufacturing process with a raw defect rate of around 1% is considered unacceptable by any reputable brand. This is one of the elephants in the digital fabrication room – just because a tool is digital doesn’t mean it will fabricate things perfectly with a push of the button. Every tool needs maintenance, and more often than not a skilled operator is required to inspect the final product and polish over rough edges.
To better grasp the magnitude of the factory test problem, consider the software that’s loaded on your computer. How did it get in there? Devices come out of the silicon foundry mostly blank. They typically don’t even have the innate knowledge to traverse a filesystem, much less connect to the Internet to download an update. Yet everyone has had the experience of waiting for an update to download and install. Factories must orchestrate a much more time-consuming and complicated process to bootstrap every device made, in order for you to enjoy the privilege of connecting to the Internet to download updates.
One might think, “surely, there must be a standardized way for handling this”.
Shockingly, there isn’t.
How Not To Test a Product
Unfortunately, first-time product makers often make the assumption that either products don’t require 100% testing (because the boards are assembled by robots, and robots don’t make mistakes, right?), or there is some otherwise standardized way to handle the initial firmware upload. Once upon a time, I was called upon to intervene on a factory test for an Arduino-derivative product, where the original test specification was literally “plug the device into the USB port of [your] laptop, and type in this AVRDUDE command to load code, and then type in another AVRDUDE command to set the fuses, and then use a multimeter to check the voltages on these two test points”. The test documentation was literally two photographs of the laptop screen and a paragraph of text. The product’s designer argued to the factory that this was sufficient because it it’s really quick and reliable: he does it in under two minutes, how could any competent factory that handles products with AVR chips not have heard of AVRDUDE, and besides he encountered no defects in the half dozen prototypes he produced by hand. This is in addition to an over-arching attitude of “whatever, I’m the smart guy who comes up with the ideas, just get your minimum-wage Chinese laborers to stop messing them up”.
The reality is that asking someone to manually run commands from a shell and read a meter for hours on end while expecting zero defects is neither humane nor practical. Furthermore, assuming the ability and judgment to run command line scripts isn’t realistic; testing is time-consuming, and thus often the least-skilled, lowest wage laborers are employed for the process. Ironically, there is no correlation between the skills required to assemble a computer, and the skills required to operate a computer. Thus, in order for the factory to meet the product designer’s expectation of low labor cost with simultaneously high quality, it’s up to the product designer to come up with an automated, fool-proof test jig.
Introducing the Test Jig: The Product Behind the Product
“Test jig” is a generic term any tool designed to assist with production testing. However, there is a basic format for a test jig chassis, and demand for test jig chassis is so high in places like Shenzhen that entire cottage industries have sprung up to support the demand. Most circuit board test jigs look a bit like this:

Above: NeTV2 circuit board test jig
And the short video below highlights the spring-loaded pogo pins of the test jig, along with how a circuit board is inserted into a test jig and clamped in place for testing.
Above: Inserting an NeTV2 PCB into its test jig.
As you can see in the video, the circuit board is placed into a precision-milled platter that moves along spring-loaded rails, allowing the board to engage with pogo-pin style test points underneath. As test points consume precious space on the circuit board, the overall mechanical accuracy of the system has to be better than +/-1mm once all tolerances are considered over thousands of cycles of wear and tear, in order to keep the test points a reasonable size (under 2mm in diameter).
The specific test jig shown above measures 12 separate DC voltages, performs a basic JTAG ID code check on the FPGA, loads firmware, and tests the on-board DRAM all in under 20 seconds. It’s the preliminary “fast test” of the NeTV2 product, meant to screen out gross solder faults and it provides an estimated coverage of about 80% of the solder joints on the PCB. The remaining 20% of the solder joints belong principally to connectors, which require a much more labor-intensive manual test to check.
Here’s a look inside the test jig:

If it looks complicated, that’s because it is. Test jig complexity is correlated with product complexity, which is why I like to say the test jig is the “product behind the product”. In some cases, a product designer may spend even more time designing a test jig than they spend designing the product itself. There’s a very large space of problems to consider when implementing a test jig, ranging from test coverage to operator fatigue, and of course throughput and reliability.
Here’s a list of the basic issues to consider when designing a test jig:
- Coverage: How to test every single feature?
- UX: Who is interpreting your test data? How to internationalize the UI by using symbols and colors instead of text, and how to minimize operator fatigue?
- Automation: What’s the quickest way to set up and tear down tests? How to avoid relying on human judgment?
- Audit & traceability: How do you enforce testing standards? How to incorporate logging and coupons to facilitate material traceability?
- Updates: What do you do when the tester needs a patch or update? How do you keep the test program in lock-step with the current firmware release?
- Responsibility: Who is responsible for product quality? How do you create a natural incentive to design-for-test from the very first product sketch?
- Code Structure: How do you maintain the tester’s code base? It’s tempting to think that test jig code should be write-once, since it’s going into a single device with a limited user base. However, the reality of production is rarely so simple, and it pays to structure your code base so that it’s self-checking, modular, reconfigurable, and reliable.
Each of these bullet points are aspects of test jig design that I have learned from the school of hard knocks.
Read on, and avoid my mistakes.
Coverage
Ideally, a tester should cover 100% of the features of a product. But what, exactly, constitutes a feature? I once designed a product called the Chumby One, and I also designed its test procedure. I tried my best to cover all of its features, but I missed one: the power button. It seemed simple enough – just a switch, what could go wrong? It turns out that over the course of production, the tolerance between the mechanical switch pusher and the electrical switch mechanism had drifted to the point where pushing on the cap would not contact the electrical switch itself, leading to a cohort of returns from that production lot.
Even the simplest of mechanisms is a feature that needs to be tested.
Since that experience, I’ve adopted an “inside/outside” methodology to derive the test feature list. First, I look “inside” the product, going through the schematic and picking key features for testing. The priority is to check for solder faults as quickly as possible, based on the assumption that the constituent components are 100% pre-tested and reliable. Then, I look at the product from the “outside”, as a consumer might approach it. First, I look at the marketing brochure and see what was promised: “world class WiFi performance” demands a different level of test from “product has WiFi”. Then, I try to imagine all the ways a customer might interact with the product – such as pressing the power button – and add those points to the test list. This means every connector needs to have something stuffed in it, every switch pressed, every indicator light must get checked.

Red arrow calls out the mechanical switch pusher that drifted out of tolerance with the corresponding electrical switch
UX
Test jig UX can have a large impact on test throughput and reliability; test operators are human, and like all humans are susceptible to fatigue and boredom. A startup I worked with once told me a story of how a simple UX change drastically improved test throughput. They had a test that would take 10 minutes on average to run, so in order to achieve a net throughput of around 1 minute per unit, they provided the factory 10 testers. Significantly, the test run-time would vary from unit to unit, with a variance of several minutes from unit to unit. Unfortunately, the only indicator of test state was a single light that could either flash or change color. Furthermore, the lighting pattern of units that failed testing bore a resemblance to units that were still running the test, so even when the operator noticed a unit that finished testing, they would often overlook failed units, assuming they were still running the test. As a result, the actual throughput achieved on their first production run was about one unit every 5 minutes — driving up labor costs dramatically.
Once the they refactored the UX to include an audible chime that would play when the test was finished, aggregate test cycle time dropped to a bit over a minute – much closer to the original estimate.
Thus, while one might think UX is just for users, I’ve found it pays to make wireframes and mock-ups for the tester itself, and to spend some developer cycles to create an operator-friendly test program. In some ways, tester UX design is more challenging than the product UX: ideally, you’re creating a UX with icons that are internationally recognizeable, using little or no text, so operators anywhere in the world can just sit down and use it with no special training. Furthermore, you’re trying to create user engagement with something as banal as a test – something that’s literally as boring as watching paint dry. I’ve even gone so far as putting a mini-game in the middle of a long test sequence to keep operators attentive. The mini-game was of course directly relevant to the testing certain hardware sensors, but it was surprisingly effective because the operators would race each other on the mini-game to see who could finish the fastest, boosting throughput and increasing worker happiness.
At the end of the day, factories are powered by humans, and it pays to employ a human-first design process when crafting test programs.
Automation
Human operators are prone to error. The more a test can be automated, the more reliable it can be, and in the long run automation will save money. I once visited a large mobile phone maker’s factory, and witnessed a gymnasium-sized room full of test stations replaced by a pair of fully robotic test stations. Instead of hundreds of operators plugging cables in and checking aspects like screen and camera quality, a delicate ballet of robotic actuators would plug connectors into every port in a fraction of a second, and every feature of the phone from the camera to the GPS is tested in a couple of minutes. The test stations apparently cost about a million dollars to develop, but the empty cavern of idle test jigs sitting next to it was clear testament to the labor cost savings of such a high degree of automation.
At the smaller scales more typical of startups, automation can happen but it needs to be judiciously applied. Every robotic actuator takes time and money to develop, and they are also prone to wear-out and eventual failure. For the Chibitronics Chibi Chip product, there’s a single mechanical switch on the board, and we developed a simple servo mechanism to actuate the plunger. However, despite using a series-elastic spring and a foam pad to avoid over-stressing the servo motor, over time, we’ve found the motor still fails, and operators have disconnected it in favor of manually pushing the button at the right time.

The Chibi Chip test jig

Detail view of the reset switch servo
Indicator lights can also be tricky to test because the lighting conditions in a factory can be highly variable. Sometimes the floor is flooded by sunlight; other times, it’s lit by dim fluorescent lamps or LED bulbs, each with distinct noise signatures. A simple photodetector will be unreliable unless you can perfectly shield the device under test (DUT) from stray light sources. However, if the product’s LEDs can be modulated (with a PWM waveform, for example), the modulation can be detected through an AC-coupled photodetector. This system tends to be more reliable as the AC coupling rejects sunlight, and the modulation frequency can be chosen to be distinct from other stray light noise sources in the factory.
In general, the gold standard for test automation is to put the DUT into a jig, press a button, wait, and then a red or green light indicates if the device passes or fails. For simple products, this should be achievable, but reasonable exceptions should be made depending upon the resources available in a startup to implement tests versus the potential frequency and impact of a particular feature escaping the test process. For example, in the case of NeTV2, the functionality of indicator LEDs and the fan are visually inspected by the operator; but in my judgment, all the components involved have generous tolerances and are less likely to be assembled incorrectly, and there are other points downstream of the PCB test during the assembly process where the LEDs and fan operation will be checked yet again, further reducing the likelihood of these features escaping the test process.
Audit and Traceability
Here’s a typical failure scenario at a factory: one operator is running two testers in parallel. The lunch bell rings, and the operator gets up and leaves without noting the status of the test (if you’ve been doing the same thing over and over for the past four hours and running on an empty belly, you’d do the same thing too). After lunch, the operator sits down again, and has to recall whether the units in front of her have been tested or not. As a result of this arbitrary judgment call, sometimes units that didn’t pass test, or weren’t even tested at all, slip into the tested product bins after a shift change.
This is one of the many reasons why it pays to incorporate some sort of audit and traceability program into the tester and product itself. The exact nature of the program will depend greatly upon the exact nature of the product and amount of developer resources available, but a simple example is structuring the test program so that a serial number isn’t generated for the product until all the tests pass – thus, the serial number is a kind of “coupon” to prove the unit has passed test. In the operator-returning-from-lunch scenario, she just has to check for the presence of a serial number to determine the testing state of a particular unit.

The Chibi Chip uses Bitmarks as a coupon to indicate when they have passed test. The Bitmarks also help prevent warranty fraud and deters cloning.
Sometimes I also burn a log of the test into the product itself. It’s important to make the log a circular buffer that can store more than one test run, because often times products that fail test the first time must be retested several times as it’s reworked and repaired. This way, if a product is returned by a user, I can query the log and see a fairly complete history of the product’s rework experience in the factory. This is incredibly helpful in debugging factory process issues and holding the factory accountable for marginal practices such as re-testing a device multiple times without repairing it, with the hope that they get lucky and get a “pass” out of the tester due to random environmental fluctuations.
Ideally, these logs are sent up to the cloud or a server directly, but that will depend heavily upon the reliability of the Internet connectivity at your facility. Internet is notoriously unreliable in China, especially to servers not located on the mainland, and so sometimes a small startup with limited resources has to make compromises about the extent and nature of audit and traceability achievable on the factory floor.
Updates
Consumer electronic products are increasingly just software wrapped in a plastic shell. While the hardware itself must stabilize months before production, the software in a product continues to evolve, especially in Internet-connected products that support over-the-air updates. Sometimes patches to a product’s firmware can profoundly alter low-level APIs, breaking the factory test program. For example, I had a product once where the audio drivers went through a major upgrade, going from OSS to ALSA. This changed the way the microphone subsystem was accessed, causing the microphone test to fail in production. Thus user firmware updates can also necessitate a tester program update.
If a test jig was engineered as a stand-alone box that requires logging into a terminal to upgrade, every time the software team pushes an update, guess what – you’re hopping on a plane to the factory to log in to the test jig and upgrade it. This is not a sustainable upgrade plan for products that have complex, constantly evolving internal firmware; thus, as the test jig designer, it’s well-advised to build a secure remote upgrade process into the test jig itself.

That’s me about 12 years ago on a factory floor at 2AM debugging a testjig update gone wrong, bringing production to a screeching halt. Don’t be like me; you can do better!
In addition a remote upgrade mechanism, you’re going to need a way to validate the test jig update without having to bring down a production line. In order to help with this, I always keep a physical copy of the production test jig in my office, so I can validate testjig updates from the comfort of my office before pushing them to the production floor. I try my best to keep the local jig an exact copy of what’s on the line; this may involve taking snapshots of the firmware image or swapping out OS drives between development and production versions, or deliberately breaking features that have somehow failed on the production jigs. This process is inspired by the engineers at JPL and NASA who keep an exact copy of Mars-based rovers on Earth, so they can thoroughly test an update before pushing it to the rover on Mars. While this discipline can be inconvenient and incurs the cost of an extra test jig, it’s inevitably cheaper than having to book a last minute flight to your factory to fix things because of an update gone wrong.
As for the upgrade mechanism itself, how fancy and secure you want to get has virtually no limit; I’ve done everything from manual swaps of USB thumb drives that contain the tester configuration data to a private VPN via a dedicated 3G-to-wifi gateway deployed at the factory site. The nature of the product (e.g. does it contain security keys, how often is the product firmware updated) and the funding level of your organization will heavily influence the architecture of the upgrade process.
Responsibility
Given how much effort it takes to build a good test jig, it’s tempting to free up precious developer resources by simply outsourcing the test jig to a third party. I’ve almost never found this to be a good idea. First of all, nobody but the developer knows what skeletons are hidden in a product’s closet. There’s what’s written in the spec, but then there is how faithfully the spec was implemented. Of course, in an ideal world, all specs were perfectly met, but only the developer has a true sense of how spot-on the implementation ended up. This drives the second point, which is avoiding the blame game. By throwing tests over the fence to a third party, if a test isn’t easy to implement or is generating false results, it’s easy to get into a finger-pointing exercise over who is at fault: the developer for not meeting the specs, or the test developer for not being creative enough to implement the test without necessitating design changes.
However, when the developer knows they are ultimately on the hook for the test jig, from day one the developer thinks about design for test. Where will the test points go? How do we make internal state easily visible? What bring-up sequence gives us the most test coverage in the shortest amount of time? By making the developer responsible for the test jig, the test program comes together as the product matures. Bring-up scripts used to validate the product are quickly converted to factory tests, and overall the product achieves a higher standard of testability while saving the money and resources that would otherwise be spent trying to coordinate between two parties with conflicting self-interests.
Code Structure
It’s tempting to think about a test jig as a pile of write-once code that doesn’t need to be maintainable. For simple products, one can definitely get away with this mentality. However, I’ve been bitten more than once by fragile code bases inside production testers. The most typical scenario where things break is when I have to change the order of tests, in order to prioritize testing problematic features first. It doesn’t make sense to test a dozen high-yielding features before running a test on a feature with a known yield issue. That just wastes operator time, and runs up the cost of production.
It’s also hard to predict before production what the most frequent mode of failure would be – after all, any failures you could have anticipated would already be designed out! So, quite often in the middle of an early production run, I’m challenged with having to change the order of tests in a complex sequence of tests to optimize operator time and improve production throughput.
Tests almost always have dependencies – you have to power on the board before you can flash the firmware; you need firmware before you can connect to wifi; you need credentials to connect to wifi; you have to clean up the test credentials before shipping the product. However, if the process that cleans up the test credentials is also responsible for cleaning up any other temporary tester files (for example, a flag that also sets Bluetooth into test mode), moving the wifi test sequence earlier could result in tester configuration files being left on the customer image, potentially leading to unexpected behaviors (such as Bluetooth still being in test mode in the shipping product!).
Thus, it’s helpful to have some infrastructure for tests that keeps each test modular while enforcing dependencies. Although one could write this code every single time from scratch, we encounter this problem so regularly that Sean ‘Xobs’ Cross set out to create a testjig management system to solve this problem “once and for all”. The result is a project he calls Exclave, with the idea being that Exclave – like an actual geographical exclave – is a tiny bit of territory that you can retain control of inside a foreign factory.
Introducing Exclave
Exclave is a scaffold designed to give structure to an otherwise amorphous blob of test code, while minimizing the amount of overhead required of the product designer to achieve this structure. The basic features of Exclave are as follows:
- Code Re-use. During product bring-up, designers write simple scripts to validate each feature individually. Exclave attempts to re-use these scripts by making no assumption about the language used to write them. Python, C, Bash, Node.js, Rust – all are welcome, so long as they run on a command line and can return an exit code.
- Automated dependency resolution. Each test routine is associated with a “.test” descriptor which describes the dependencies and timeout for a given script, which are then automatically resolved by Exclave.
- Scenario management. Test descriptors are strung together into scenarios, which can be selected dynamically based on the real-time requirements of the factory.
- Triggers. Typically a test is started by pressing a button, but Exclave’s flexible triggering system also allows tests to start on other cues, such as hot-plug events.
- Multiple UI targets. Test jig UI can range from a red/green light to a serial console device to a full graphical interface running on a monitor. Exclave has a system for interpreting test results and driving multiple UI sinks. This allows for fast product debugging by attaching a GUI (via an HDMI monitor or laptop) while maintaining compatibility with cost-efficient LED indicators favored for production scale-up.
Above: Exclave helps migrate lab-bench validation code to production-grade factory tests.
To get a little flavor on what Exclave looks like in practice, let’s look at a couple of the tests implemented in the NeTV2 production test flow. First, the production test is split into two repositories: the test descriptors, and the graphical UI. Note that by housing all the tests in github, we also solve the tester upgrade problem by providing the factory with a set git repo management scripts mapped to double-clickable desktop icons.
These repositories are installed on a Raspberry Pi contained within the test jig, and Exclave is started on boot as a systemd service. The service runs a simple script that fires up Exclave in a target directory which contains a “.jig” file. The “netv2.jig” file specifies the default scenario, among other things.
Here’s an example of what a quick test scenario looks like:
This scenario runs a variety of scripts in different languages that: turn on the device (bash/C), checks voltages (C), checks ID code of the FPGA (bash/openOCD), loads a test bitstream (bash/openOCD), checks that the REPL shell can start on the FPGA (Expect/TCL), and then runs a RAM test (Expect/TCL) before shutting the board down (bash/C). Many of these scripts were copied directly from code used during board bring-up and system validation.
A basic operation that’s surprisingly tricky to do right is checking for terminal interaction (REPL shell) via serial port. Writing a C or bash script that does this correctly and gracefully handles all error cases is hard, but fortunately someone already solved this problem with the “Expect” TCL extension. Here’s what the REPL shell test descriptor looks like in Exclave:
As you can see, this points to a couple other tests as dependencies, sets a time-out, and also designates the location of the Expect script.
And this is what the Expect script looks like:
This one is a bit more specialized to the NeTV2, but basically, it looks for the NeTV2 tester firmware shell prompt, which is “TESTER_NX8D>”; the system will attempt to recover this prompt by sending a carriage-return sequence once every two seconds and searching for this special string in return. If it receives the string “BIOS” instead, this indicates that the NeTV2 failed to boot and escaped into the ROM BIOS, probably due to a RAM error; at which point, the Expect script prints a bunch of JSON, which is automatically passed up to the UI layer by Exclave to create a human-readable error message.
Which brings us to the interface layer. The NeTV2 jig has two options for UI: a set of LEDs, or an HDMI monitor. In an ideal world, the total amount of information an operator needs to know about a board is if it passed or failed – a green or red LED. Multiple instances of the test jig are needed when a product enters high volume production (thousands of units per day), so the cost of each test jig becomes a factor during production scale-up. LEDs are orders of magnitude cheaper than an HDMI monitor, and in general a test jig will cost less than an HDMI monitor. So LEDs instead of an HDMI monitor for UI can dramatically slash the cost to scale up production. On the other hand, a pair of LEDs does not give enough information to diagnose what’s gone wrong with a bad board. In a volume production scenario, one would typically collect the (hopefully small) fraction of failed boards and bring them to a secondary station where a more skilled technician debugs them. Exclave allows the same jig used in production to be placed at the debug station, but with an HDMI monitor attached to provide valuable detailed error reports.
With Exclave, both UI are integrated seamlessly using “.interface” files. Below is an example of the .interface file that starts up the http daemon to enable JSON debugging via an HDMI monitor.
In a nutshell, Exclave contains an event reporting system, which logs events in a fashion similar to Linux kernel messages. Events are tagged with metadata, such as severity, and the events are broadcast to interface handlers that further refine them for the respective UI element. In the case of the LEDs, it just listens for “START” [a scenario], “FAIL” [a test], and “FINISH” [a scenario] events, and ignores everything else. In the case of the HDMI interface, a browser configured to run in kiosk mode is pointed to the correct localhost webpage, and a jquery-based HTML document handles the dynamic generation of the UI based upon detailed messages from Exclave. Below is a screenshot of what the UI looks like in action.
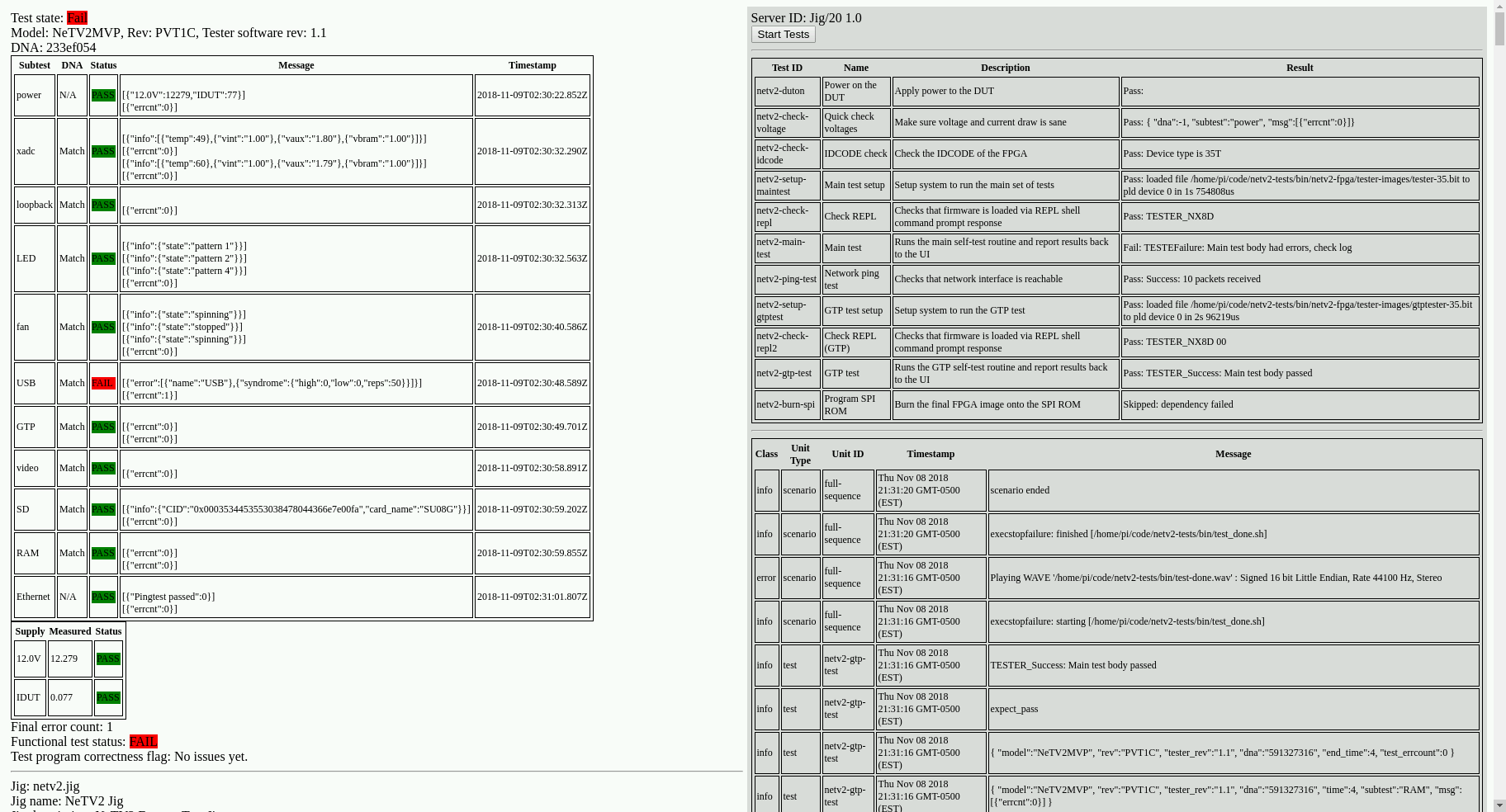
The UI is deliberately brutalist in design, using color to highlight only the most important messages, and also includes audible alerts so that operators can zone out while the test runs.
As you can see, the NeTV2 production tester tests everything – from the LEDs to the Ethernet, to features that perhaps few people will ever use, such as the SD card slot and every single GPIO pin. Thanks to Exclave, I was able to get this complex set of tests up and running in under a month: the first code commit was made on Oct 13, 2018, and by Nov 7, I was largely just tweaking tests for performance, and to reflect operational realities discovered on the factory floor.
Also, for the hardware-curious, I did design a custom “hat” for the Raspberry Pi to add several ADC channels and various connectors to facilitate testing. You can check out the source for the tester hat at the Alphamax github repo. I had six of these boards built; five of them have found their way into various parts of the NeTV2 production flow, and if I still have one spare after production is stabilized, I’m planning on installing a replica of a tester at HAX in Shenzhen. That way, those curious to find out more about Exclave can walk up to the tester, log into it, and poke around (assuming HAX agrees to this).
Let’s Stop Re-Inventing the Test Jig!
The unspoken secret of hardware is that behind every product, there’s a robust test jig making sure that every unit shipped to end customers meets quality standards. Hardware startups that don’t anticipate the importance and difficulty of creating such a tester often encounter acute (and sometimes fatal) growing pains. Anytime I build more than a few copies of a piece of hardware, I know I’m going to need a test jig – even for bespoke, short-run products like a conference badge.
After spending months of agony re-inventing the wheel every time we shipped a product, Xobs decided to create Exclave. It’s still a work in progress, but by now it’s been used as the production test infrastructure for several volume products, including the Chibi Chip, Chibi Scope, Tomu, The Phage Blinky Badge, and now NeTV2 (those are all links to the actual Exclave test scripts for each of the respective products — open source ftw!). I feel Exclave has come along far enough that it’s time to invite more users to join the Exclave community and give it a try. The code is located on github and is 100% open source, and it’s written in Rust entirely by Xobs. It’s my hope that Exclave can mature into a tool and a community that will save countless Makers and small hardware startups the teething pains of re-inventing the test jig.

Production-proven testjigs that run Exclave. Clockwise from top-right: NeTV2, Chibi Chip, Chibi Scope, Tomu, and The Phage Blinky Badge. The badge tester has even survived a couple of weeks exposed to the harsh elements of the desert as a DIY firmware updating station!
[…] Exclave: Hardware Testing in Mass Production, Made Easier 11 by lnmx | 1 comments on Hacker News. […]
[…] Exclave: Hardware Testing in Mass Production, Made Easier 11 by lnmx | 1 comments on Hacker News. […]
[…] Exclave: Hardware Testing in Mass Production, Made Easier 11 by lnmx | 1 comments on Hacker News. […]
[…] Exclave: Hardware Testing in Mass Production, Made Easier 11 by lnmx | 1 comments on Hacker News. […]
[…] Exclave: Hardware Testing in Mass Production, Made Easier 12 by lnmx | 1 comments on Hacker News. […]
Thank you VERY much for writing this informative article on test jigs and Exclave.
I went to https://github.com/eNclave, but there were zero repositories. Realized my mistake and went to https://github.com/eXclave. Bingo.
Refreshed my knowledge about the difference between enclaves and exclaves on Wikipedia. https://en.wikipedia.org/wiki/Enclave_and_exclave
Mentioning it here in case anyone else makes the same mistake.
Hey! Great article. Just a random thought: in your “introducing exclave” paragraph, a number of things struck my mind, namely: “Automated dependency resolution” and “triggers”. I realized that this feels very similar to using directed acyclic graphs in configuration management to get things done.
For what it’s worth, my project is an open source tool that does just that. It was never intended for something in this area, but it’s a general purpose engine that can do that work. In the odd chance you’re interested, please feel free to give me a shout or have a look: https://github.com/purpleidea/mgmt/
Cheers and good luck!
Neat!
One thing that can help when a test has to be by operator inspection, is to include ‘fake failures’ at some rate. For example, we had a product with 128 RGB LEDs, some of the time my test would simulate a failure of some LED and only pass the test if the operator chose the ‘fail’ button. (The test is repeated until the random choice is not to simulate failure).
With 128 LEDs it turned out to be important that the operator was on the ball, because the failure rate before rework was massive.
Thanks for the thorough post on testing, will have to have a closer look at Exclave as I am involved with a test jig at the moment :D
[…] xclave: Hardware Testing in Mass Production, Made Easier. […]
I’m reminded of a software dev who wrote the disk format utility for an early PC. While testing it, he accidentally typed ‘y’ when asked, “Ready to format?”, wiping out important data. Annoyed at his destructive typo, he changed the utility so you had to type “Yes I really mean it” when asked to proceed with the disk format.
Fast forward a year or so later, he visits a factory using his utility to format drives in new computers. He discovers to his horror a few employees whose full-time job was to type “Yes I really mean it” over and over, on each new PC.
[…] The post has a lot of other good tips and insight into testing. Read the whole thing over at bunnie’s blog. […]
I’m in Shenzhen now deploying our first Exclave-based test jig. There were a few wrinkles porting over some of the existing test framework to work with Exclave but overall I’m super happy with how it’s gone.
Thank you Bunnie and Xobs for opening this tool up for he rest of us. Hopefully I can tidy up the bits and piece’s I’ve done and convince my employer to let me release them into the Exclave ecosystem.
Amazing! Thanks for using it, and also thanks for leaving feedback. :)
Thanks for the article. It gave us the motivation to open-source our framework for test station.
https://github.com/FeetMe/sopic/
Not the same approach as exclave, it’s higher level, restrict the language to write tests, but come with a different set of features.
Good post