Note: this post uses a $\LaTeX$ plugin to render math symbols. It may require a desktop browser for the full experience…
The “double ratchet” algorithm is integral to modern end-to-end-encrypted chat apps, such as Signal, WhatsApp, and Matrix. It gives encrypted conversations the properties of resilience, forward secrecy, and break-in recovery; basically, even if an adversary can manipulate or observe portions of an exchange, including certain secret materials, the damage is limited with each turn of the double ratchet.
The double-ratchet algorithm is a soup of cryptographic components, but one of the most computationally expensive portions is the “Diffie-Hellman (DH) key exchange”, using Elliptic Curve Diffie-Hellman (ECDH) with Curve25519. How expensive? This post from 2020 claims a speed record of 3.2 million cycles on a Cortex-M0 for just one of the core mathematical operations: fairly hefty. A benchmark of the x25519-dalek Rust crate on a 100 MHz RV32-IMAC implementation clocks in at 100ms per DH key exchange, of which several are involved in a double-ratchet. Thus, any chat client implementation on a small embedded CPU would suffer from significant UI lag.
There are a few strategies to rectify this, ranging from adding a second CPU core to off-load the crypto, to making a full-custom hardware accelerator. Adding a second RISC-V CPU core is expedient, but it wouldn’t do much to force me to understand what I was doing as far as the crypto goes; and there’s already a strong contingent of folks working on multi-core RISC-V on FPGA implementations. The last time I implemented a crypto algorithm was for RSA on a low-end STM32 back in the mid 2000’s. I really enjoyed getting into the guts of the algorithm and stretching my understanding of the underlying mathematical primitives. So, I decided to indulge my urge to tinker, and make a custom hardware accelerator for Curve25519 using Litex/Migen and Rust bindings.
What the Heck Is $\mathbf{{F}}_{{{{2^{{255}}}}-19}}$?
I wanted the accelerator primitive to plug directly into the Rust Dalek Cryptography crates, so that I would be as light-fingered as possible with respect to changes that could lead to fatal flaws in the broader cryptosystem. I built some simple benchmarks and profiled where the most time was being spent doing a double-ratchet using the Dalek Crypto crates, and the vast majority of the time for a DH key exchange was burned in the Montgomery Multiply operation. I won’t pretend to understand all the fancy math-terms, but people smarter than me call it a “scalar multiply”, and it actually consists of thousands of “regular” multiplies on 255-bit numbers, with modular reductions in the prime field $\mathbf{{F}}_{{{{2^{{255}}}}-19}}$, among other things.
Wait, what? So many articles and journals I read on the topic just talk about prime fields, modular reduction and blah blah blah like it’s asking someone to buy milk and eggs at the grocery store. It was a real struggle to try and make sense of all the tricks used to do a modular multiply, much less to say even elliptic curve point transformations.
Well, that’s the point of trying to implement it myself — by building an engine, maybe you won’t understand all the hydrodynamic nuances around fuel injection, but you’ll at least gain an appreciation for what a fuel injector is. Likewise, I can’t say I deeply understand the number theory, but from what I can tell multiplication in $\mathbf{{F}}_{{{{2^{{255}}}}-19}}$ is basically the same as a “regular 255-bit multiply” except you do a modulo (you know, the `%` operator) against the number $2^{{255}}-19$ when you’re done. There’s a dense paper by Daniel J. Bernstein, the inventor of Curve25519, which I tried to read several times. One fact I gleaned is part of the brilliance of Curve25519 is that arithmetic modulo $2^{{255}}-19$ is quite close to regular binary arithmetic except you just need to special-case 19 outcomes out of $2^{{255}}$. Also, I learned that the prime modulus, $2^{{255}}-19$, is where the “25519” comes from in the name of the algorithm (I know, I know, I’m slow!).
After a whole lot more research I stumbled on a paper by Furkan Turan and Ingrid Verbauwhede that broke down the algorithm into terms I could better understand. Attempts to reach out to them to get a copy of the source code was, of course, fruitless. It’s a weird thing about academics — they like to write papers and “share ideas”, but it’s very hard to get source code from them. I guess that’s yet another reason why I never made it in academia — I hate writing papers, but I like sharing source code. Anyways, the key insight from their paper is that you can break a 255-bit multiply down into operations on smaller, 17-bit units called “limbs” — get it? digits are your fingers, limbs (like your arms) hold multiple digits. These 17-bit limbs map neatly into 15 Xilinx 7-Series DSP48E block (which has a fast 27×18-bit multiplier): 17 * 15 = 255. Using this trick we can decompose multiplication in $\mathbf{{F}}_{{{{2^{{255}}}}-19}}$ into the following steps:
- Schoolbook multiplication with 17-bit “limbs”
- Collapse partial sums
- Propagate carries
- Is the sum $\geq$ $2^{{255}}-19$?
- If yes, add 19; else add 0
- Propagate carries again, in case the addition by 19 causes overflows
The multiplier would run about 30% faster if step (6) were skipped. This step happens in a fairly small minority of cases, maybe a fraction of 1%, and the worst-case carry propagate through every 17-bit limb is diminishingly rare. The test for whether or not to propagate carries is fairly straightforward. However, short-circuiting the carry propagate step based upon the properties of the data creates a timing side-channel. Therefore, we prefer a slower but safer implementation, even if we are spending a bunch of cycles propagating zeros most of the time.
Buckle up, because I’m about to go through each step in the algorithm in a lot of detail. One motivation of the exercise was to try to understand the math a bit better, after all!
TL;DR: Magic Numbers
If you’re skimming this article, you’ll see the numbers “19” and “17” come up over and over again. Here’s a quick TL;DR:
- 19 is the tiny amount subtracted from $2^{{255}}$ to arrive at a prime number which is the largest number allowed in Curve25519. Overflowing this number causes things to wrap back to 0. Powers of 2 map efficiently onto binary hardware, and thus this representation is quite nice for hardware people like me.
- 17 is a number of bits that conveniently divides 255, and fits into a single DSP hardware primitive (DSP48E) that is available on the target device (Xilinx 7-series FPGA) that we’re using in this post. Thus the name of the game is to split up this 255-bit number into 17-bit chunks (called “limbs”).
Schoolbook Multiplication
The first step in the algorithm is called “schoolbook multiplication”. It’s like the kind of multiplication you learned in elementary or primary school, where you write out the digits in two lines, multiply each digit in the top line by successive digits in the bottom line to create successively shifted partial sums that are then added to create the final result. Of course, there is a twist. Below is what actual schoolbook multiplication would be like, if you had a pair of numbers that were split into three “limbs”, denoted as A[2:0] and B[2:0]. Recall that a limb is not necessarily a single bit; in our case a limb is 17 bits.
| A2 A1 A0
x | B2 B1 B0
------------------------------------------
| A2*B0 A1*B0 A0*B0
A2*B1 | A1*B1 A0*B1
A2*B2 A1*B2 | A0*B2
(overflow) (not overflowing)
The result of schoolbook multiplication is a result that potentially has 2x the number of limbs than the either multiplicand.
Mapping the overflow back into the prime field (e.g. wrapping the overflow around) is a process called reduction. It turns out that for a prime field like $\mathbf{{F}}_{{{{2^{{255}}}}-19}}$, reduction works out to taking the limbs that extend beyond the base number of limbs in the field, shifting them right by the number of limbs, multiplying it by 19, and adding it back in; and if the result isn’t a member of the field, add 19 one last time, and take the result as just the bottom 255 bits (ignore any carry overflow). If this seems magical to you, you’re not alone. I had to draw it out before I could understand it.
This trick works because the form of the field is $2^{{n}}-p$: it is a power of 2, reduced by some small amount $p$. By starting from a power of 2, most of the binary numbers representable in an n-bit word are valid members of the field. The only ones that are not valid field members are the numbers that are equal to $2^{{n}}-p$ but less than $2^{{n}}-1$ (the biggest number that fits in n bits). To turn these invalid binary numbers into members of the field, you just need to add $p$, and the reduction is complete.
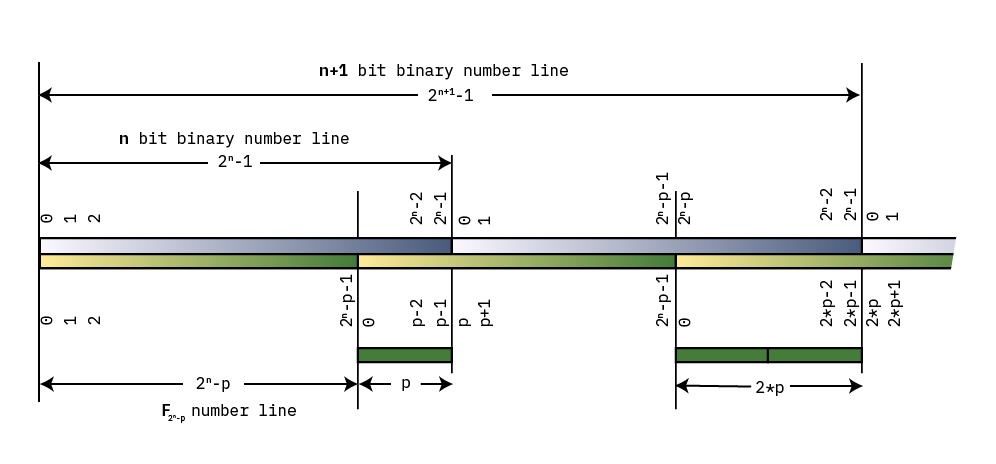
A diagram illustrating modular reduction
The diagram above draws out the number lines for both a simple binary number line, and for some field $\mathbf{{F}}_{{{{2^{{n}}}}-p}}$. Both lines start at 0 on the left, and increment until they roll over. The point at which $\mathbf{{F}}_{{{{2^{{n}}}}-p}}$ rolls over is a distance $p$ from the end of the binary number line: thus, we can observe that $2^{{n}}-1$ reduces to $p-1$. Adding 1 results in $2^{{n}}$, which reduces to $p$: that is, the top bit, wrapped around, and multiplied by $p$.
As we continue toward the right, the numbers continue to go up and wrap around, and for each wrap the distance between the “plain old binary” wrap point and the $\mathbf{{F}}_{{{{2^{{n}}}}-p}}$ wrap point increases by a factor of $p$, such that $2^{{n+1}}$ reduces to $2*p$. Thus modular reduction of natural binary numbers that are larger than our field $2^{{n}}-p$ consists of taking the bits that overflow an $n$-bit representation, shifting them to the right by $n$, and multiplying by $p$.
In order to convince myself this is true, I tried out a more computationally tractable example than $\mathbf{{F}}_{{{{2^{{255}}}}-19}}$: the prime field $\mathbf{{F}}_{{{{2^{{6}}}}-5}} = 59$. The members of the field are from 0-58, and reduction is done by taking any number modulo 59. Thus, the number 59 reduces to 0; 60 reduces to 1; 61 reduces to 2, and so forth, until we get to 64, which reduces to 5 — the value of the overflowed bits (1) times $p$.
Let’s look at some more examples. First, recall that the biggest member of the field, 58, in binary is 0b00_11_1010.
Let’s consider a simple case where we are presented a partial sum that overflows the field by one bit, say, the number 0b01_11_0000, which is decimal 112. In this case, we take the overflowed bit, shift it to the right, multiply by 5:
0b01_11_0000 ^ move this bit to the right multiply by 0b101 (5) 0b00_11_0000 + 0b101 = 0b00_11_0101 = 53
And we can confirm using a calculator that 112 % 59 = 53. Now let’s overflow by yet another bit, say, the number 0b11_11_0000. Let’s try the math again:
0b11_11_0000 ^ move to the right and multiply by 0b101: 0b101 * 0b11 = 0b1111 0b00_11_0000 + 0b1111 = 0b00_11_1111
This result is still not a member of the field, as the maximum value is 0b0011_1010. In this case, we need to add the number 5 once again to resolve this “special-case” overflow where we have a binary number that fits in $n$ bits but is in that sliver between $2^{{n}}-p$ and $2^{{n}}-1$:
0b00_11_1111 + 0b101 = 0b01_00_0100
At this step, we can discard the MSB overflow, and the result is 0b0100 = 4; and we can check with a calculator that 240 % 59 = 4.
Therefore, when doing schoolbook multiplication, the partial products that start to overflow to the left can be brought back around to the right hand side, after multiplying by $p$, in this case, the number 19. This magical property is one of the reasons why $\mathbf{{F}}_{{{{2^{{255}}}}-19}}$ is quite amenable to math on binary machines.
Let’s use this finding to rewrite the straight schoolbook multiplication form from above, but now with the modular reduction applied to the partial sums, so it all wraps around into this compact form:
| A2 A1 A0
x | B2 B1 B0
------------------------------------------
| A2*B0 A1*B0 A0*B0
| A1*B1 A0*B1 19*A2*B1
+ | A0*B2 19*A2*B2 19*A1*B2
----------------------------
S2 S1 S0
As discussed above, each overflowed limb is wrapped around and multiplied by 19, creating a number of partial sums S[2:0] that now has as many terms as there are limbs, but with each partial sum still potentially overflowing the native width of the limb. Thus, the inputs to a limb are 17 bits wide, but we retain precision up to 48 bits during the partial sum stage, and then do a subsequent condensation of partial sums to reduce things back down to 17 bits again. The condensation is done in the next three steps, “collapse partial sums”, “propagate carries”, and finally “normalize”.
However, before moving on to those sections, there is an additional trick we need to apply for an efficient implementation of this multiplication step in hardware.
In order to minimize the amount of data movement, we observe that for each row, the “B” values are shared between all the multipliers, and the “A” values are constant along the diagonals. Thus we can avoid re-loading the “A” values every cycle by shifting the partial sums diagonally through the computation, allowing the “A” values to be loaded as “A” and “A*19” into holding register once before the computations starts, and selecting between the two options based on the step number during the computation.
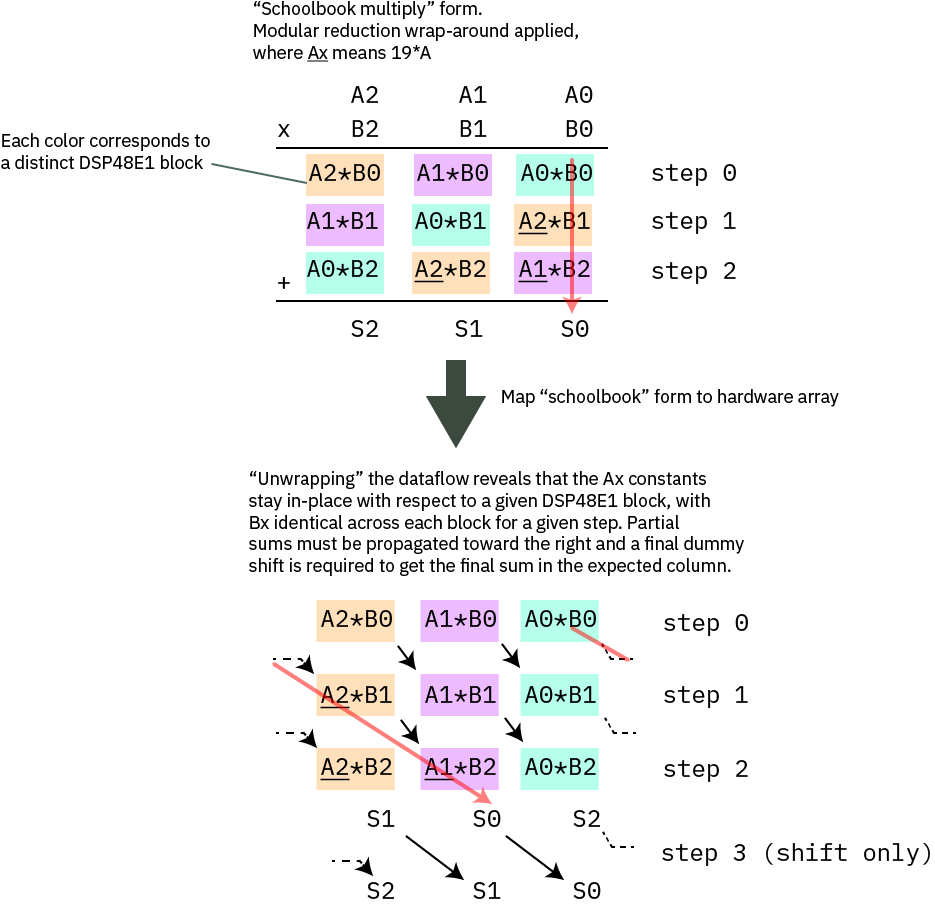
Mapping schoolbook multiply onto the hardware array to minimize data movement
The diagram above illustrates how the schoolbook multiply is mapped onto the hardware array. The top diagram is an exact redrawing of the previous text box, where the partial sums that would extend to the left have been multiplied by 19 and wrapped around. Each colored block corresponds to a given DSP48E1 block, which you may recall is a fast 27×18 multiplier hardware primitive built into our Xilinx FPGAs. The red arrow illustrates the path of a partial sum in both the schoolbook form and the unwrapped form for hardware implementation. In the bottom diagram, one can clearly see that the Ax coefficients are constant for each column, and that for each row, the Bx values are identical across all blocks in each step. Thus each column corresponds to a single DSP48E1 block. We take advantage of the ability of the DSP48E1 block to hold two selectable A values to pre-load Ax and Ax*19 before the computation starts, and we bus together the Bx values and change them in sequence with each round. The partial sums are then routed to the “down and right” to complete the mapping. The final result is one cycle shifted from the canonical mapping.
We have a one-cycle structural pipeline delay going from this step to the next one, so we use this pipeline delay to do a shift with no add by setting the `opmode` from `C+M` to `C+0` (in other words, instead of adding to the current multiplication output for the last step, we squash that input and set it to 0).
The fact that we pipeline the data also gives us an opportunity to pick up the upper limb of the partial sum collapse “for free” by copying it into the “D” register of the DSP48E1 during the shift step.
In C, the equivalent code basically looks like this:
// initialize the a_bar set of data
for( int i = 0; i < DSP17_ARRAY_LEN; i++ ) {
a_bar_dsp[i] = a_dsp[i] * 19;
}
operand p;
for( int i = 0; i < DSP17_ARRAY_LEN; i++ ) {
p[i] = 0;
}
// core multiply
for( int col = 0; col < 15; col++ ) {
for( int row = 0; row < 15; row++ ) {
if( row >= col ) {
p[row] += a_dsp[row-col] * b_dsp[col];
} else {
p[row] += a_bar_dsp[15+row-col] * b_dsp[col];
}
}
}
By leveraging the special features of the DSP48E1 blocks, in hardware this loop completes in just 15 clock cycles.
Collapse Partial Sums
At this point, the potential width of the partial sum is up to 43 bits wide. This next step divides the partial sums up into 17-bit words, and then shifts the higher to the next limbs over, allowing them to collapse into a smaller sum that overflows less.
... P2[16:0] P1[16:0] P0[16:0] ... P1[33:17] P0[33:17] P14[33:17]*19 ... P0[50:34] P14[50:34]*19 P13[50:34]*19
Again, the magic number 19 shows up to allow sums which “wrapped around” to add back in. Note that in the timing diagram you will find below, we refer to the mid- and upper- words of the shifted partial sums as “Q” and “R” respectively, because the timing diagram lacks the width within a data bubble to write out the full notation: so `Q0,1` is P14[33:17] and `R0,2` is P13[50:34] for P0[16:0].
Here’s the C code equivalent for this operation:
// the lowest limb has to handle two upper limbs wrapping around (Q/R)
prop[0] = (p[0] & 0x1ffff) +
(((p[14] * 1) >> 17) & 0x1ffff) * 19 +
(((p[13] * 1) >> 34) & 0x1ffff) * 19;
// the second lowest limb has to handle just one limb wrapping around (Q)
prop[1] = (p[1] & 0x1ffff) +
((p[0] >> 17) & 0x1ffff) +
(((p[14] * 1) >> 34) & 0x1ffff) * 19;
// the rest are just shift-and-add without the modular wrap-around
for(int bitslice = 2; bitslice < 15; bitslice += 1) {
prop[bitslice] = (p[bitslice] & 0x1ffff) + ((p[bitslice - 1] >> 17) & 0x1ffff) + ((p[bitslice - 2] >> 34));
}
This completes in 2 cycles after a one-cycle pipeline stall delay penalty to retrieve the partial sum result from the previous step.
Propagate Carries
The partial sums will generate carries, which need to be propagated down the chain. The C-code equivalent of this looks as follows:
for(int i = 0; i < 15; i++) {
if ( i+1 < 15 ) {
prop[i+1] = (prop[i] >> 17) + prop[i+1];
prop[i] = prop[i] & 0x1ffff;
}
}
The carry-propagate completes in 14 cycles. Carry-propagates are expensive!
Normalize
We’re almost there! Except that $0 \leq result \leq 2^{{256}}-1$, which is slightly larger than the range of $\mathbf{{F}}_{{{{2^{{255}}}}-19}}$.
Thus we need to check if number is somewhere in between 0x7ff….ffed and 0x7ff….ffff, or if the 256th bit will be set. In these cases, we need to add 19 to the result, so that the result is a member of the field $2^{{255}}-19$ (the 256th bit is dropped automatically when concatenating the fifteen 17-bit limbs together into the final 255-bit result).
We use another special feature of the DSP48E1 block to help accelerate the test for this case, so that it can complete in a single cycle without slowing down the machine. We use the “pattern detect” (PD) feature of the DSP48E1 to check for all “1’s” in bit positions 255-5, and a single LUT to compare the final 5 bits to check for numbers between {prime_string} and $2^{{255}}-1$. We then OR this result with the 256th bit.
If the result falls within this special “overflow” case, we add the number 19, otherwise, we add 0. Note that this add-by-19-or-0 step is implemented by pre-loading the number 19 into the A:B pipeline registers of the DSP4E1 block during the “propagate” stage. Selection of whether to add 19 or 0 relies on the fact that the DSP48E1 block has an input multiplexer to its internal adder that can pick data from multiple sources, including the ability to pick no source by loading the number 0. Thus the operation mode of the DSP48E1 is adjusted to either pull an input from A:B (that is, the number 19) or the number 0, based on the result of the overflow computation. Thus the PD feature is important in preventing this step from being rate-limiting. With the PD feature we only have to check an effective 16 intermediate results, instead of 256 raw bits, and then drive set the operation mode of the ALU.
With the help of the special DSP48E1 features, this operation completes in just a single cycle.
After adding the number 19, we have to once again propagate carries. Even if we add the number 0, we also have to “propagate carries” for constant-time operation, to avoid leaking information in the form of a timing side-channel. This is done by running the carry propagate operation described above a second time.
Once the second carry propagate is finished, we have the final result.
Potential corner case
There is a potential corner case where if the carry-propagated result going into “normalize” is between
0xFFFF_FFFF_FFFF_FFFF_FFFF_FFFF_FFFF_FFDA and 0xFFFF_FFFF_FFFF_FFFF_FFFF_FFFF_FFFF_FFEC
In this case, the top bit would be wrapped around, multiplied by 19, and added to the LSB, but the result would not be a member of $2^{{255}}-19$ (it would be one of the 19 numbers just short of $2^{{255}}-1$), and the multiplier would pass it on as if it were a valid result.
In some cases, this isn’t even a problem, because if the subsequent result goes through any operation that also includes a reduce operation, the result will still reduce correctly.
However, I do not think this corner case is possible, because the overflow path to set the high bit is from the top limb going from 0x1_FFFF -> 0x2_0000 (that is, 0x7FFFC -> 0x80000 when written MSB-aligned) due to a carry coming in from the lower limb, and it would require the carry to be very large, not just +1 as shown in the simple rollover case, but a value from 0x1_FFED-0x1_FFDB.
I don’t have a formal mathematical proof of this, but I strongly suspect that carry values going into the top limb cannot approach these large numbers, and therefore it is not possible to hit this corner case. Consider that the biggest value of a partial sum is 0x53_FFAC_0015 (0x1_FFFF * 0x1_FFFF * 15). This means the biggest value of the third overflowed 17-bit limb is 0x14. Therefore the biggest value resulting from the “collapse partial sums” stage is 0x1_FFFF + 0x1_FFFF + 0x14 = 0x4_0012. Thus the largest carry term that has to propagate is 0x4_0012 >> 17 = 2. 2 is much smaller than the amount required to trigger this condition, that is, a value in the range of 0x1_FFED-0x1_FFDB. Thus, perhaps this condition simply can’t happen? It’d be great to have a real mathematician comment if this is a real corner case…
Real Hardware
You can jump to the actual code that implements the above algorithm, but I prefer to think about implementations visually. Thus, I created this timing diagram that fully encapsulates all of the above steps, and the data movements between each part (click on the image for an editable, larger version; works best on desktop):

Block diagrams of the multiplier and even more detailed descriptions of its function can be found in our datasheet documentation. There’s actually a lot to talk about there, but the discussion rapidly veers into trade-offs on timing closure and coding technique, and farther away from the core topic of the Curve25519 algorithm itself.
Didn’t You Say We Needed Thousands of These…?
So, that was the modular multiply. We’re done right? Nope! This is just one core op in a sequence of thousands of these to do a scalar multiply. One potentially valid strategy could be to try to hang the modular multiplier off of a Wishbone bus peripheral and shove numbers at it, and come back and retrieve results some time later. However, the cost of pushing 256-bit numbers around is pretty high, and any gains from accelerating the multiply will quickly be lost in the overhead of marshaling data. After all, a recurring theme in modern computer architecture is that data movement is more expensive than the computation itself. Damn you, speed of light!
Thus, in order to achieve the performance I was hoping to get, I decided to wrap this inside a microcoded “CPU” of sorts. Really more of an “engine” than a car — if a RISC-V CPU is your every-day four-door sedan optimized for versatility and efficiency, the microcoded Curve25519 engine I created is more of a drag racer: a turbocharged engine block on wheels that’s designed to drive long flat stretches of road as fast as possible. While you could use this to drive your kids to school, you’ll have a hard time turning corners, and you’ll need to restart the engine after every red light.
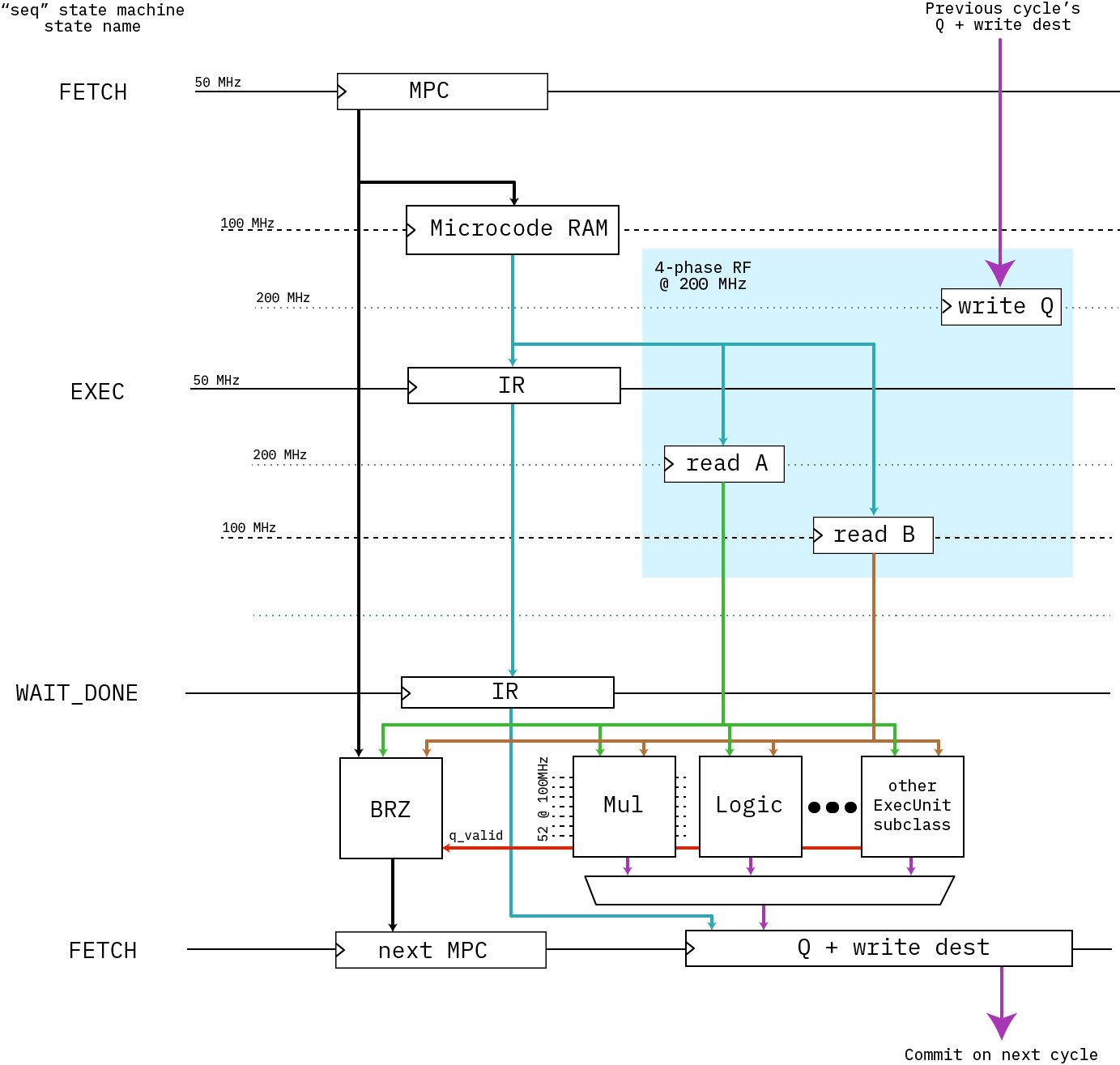
Above is a block diagram of the engine’s microcoded architecture. It’s a simple “three-stage” pipeline (FETCH/EXEC/RETIRE) that runs at 50MHz with no bypassing (that would be extremely expensive with 256-bit wide datapaths). I was originally hoping we could close timing at 100MHz, but our power-optimized -1L FPGA just wouldn’t have it; so the code sequencer runs at 50MHz; the core multiplier at 100MHz; and the register file uses four phases at 200MHz to access a simple RAM block to create a space-efficient virtual register file that runs at 50MHz.
The engine has just 13 opcodes:

There’s no compiler for it; instead, we adapted the most complicated Rust macro I’ve ever seen from johnas-schievink’s rustasm6502 crate to create the abomination that is engine25519-as. Here’s a snippet of what the assembly code looks like, in-lined as a Rust macro:
let mcode = assemble_engine25519!(
start:
// from FieldElement.invert()
// let (t19, t3) = self.pow22501(); // t19: 249..0 ; t3: 3,1,0
// let t0 = self.square(); // 1 e_0 = 2^1
mul %0, %30, %30 // self is W, e.g. %30
// let t1 = t0.square().square(); // 3 e_1 = 2^3
mul %1, %0, %0
mul %1, %1, %1
// let t2 = self * &t1; // 3,0 e_2 = 2^3 + 2^0
mul %2, %30, %1
// let t3 = &t0 * &t2; // 3,1,0
mul %3, %0, %2
// let t4 = t3.square(); // 4,2,1
mul %4, %3, %3
// let t5 = &t2 * &t4; // 4,3,2,1,0
mul %5, %2, %4
// let t6 = t5.pow2k(5); // 9,8,7,6,5
psa %28, #5 // coincidentally, constant #5 is the number 5
mul %6, %5, %5
pow2k_5:
sub %28, %28, #1 // %28 = %28 - 1
brz pow2k_5_exit, %28
mul %6, %6, %6
brz pow2k_5, #0
pow2k_5_exit:
// let t7 = &t6 * &t5; // 9,8,7,6,5,4,3,2,1,0
mul %7, %6, %5
);
The `mcode` variable is a [i32] fixed-length array, which is quite friendly to our `no_std` Rust environment that is Xous.
Fortunately, the coders of the curve25519-dalek crate did an amazing job, and the comments that surround their Rust code map directly onto our macro language, register numbers and all. So translating the entire scalar multiply inside the Montgomery structure was a fairly straightforward process, including the final affine transform.
How Well Does It Run?
The fully accelerated Montgomery multiply operation was integrated into a fork of the curve25519-dalek crate, and wrapped into some benchmarking primitives inside Xous, a small embedded operating system written by Xobs. A software-only implementation of curve25519 would take about 100ms per DH operation on a 100MHz RV32-IMAC CPU, while our hardware-accelerated version completes in about 6.7ms — about a 15x speedup. Significantly, the software-only operation does not incur the context-switch to the sandboxed hardware driver, whereas our benchmark includes the overhead of the syscall to set up and run the code; thus the actual engine itself runs a bit faster per-op than the benchmark might hint at. However, what I’m most interested in is in-application performance, and therefore I always include the overhead of swapping to the hardware driver context to give an apples-to-apples comparison of end-user application performance. More importantly, the CPU is free to do other things while the engine does it’s thing, such as servicing the network stack or updating the UX.
I think the curve25519 accelerator engine hit its goals — it strapped enough of a rocket on our little turtle of a CPU so that it’ll be able render a chat UX while doing double-ratchets as a background task. I also definitely learned more about the algorithm, although admittedly I still have a lot more to learn if I’m to say I truly understand elliptic curve cryptography. So far I’ve just shaken hands with the fuzzy monsters hiding inside the curve25519 closet; they seem like decent chaps — they’re not so scary, I just understand them poorly. A couple more interactions like this and we might even become friends. However, if I were to be honest, it probably wouldn’t be worth it to port the curve25519 accelerator engine from its current FPGA format to an ASIC form. Mask-defined silicon would run at least 5x faster, and if we needed the compute power, we’d probably find more overall system-level benefit from a second CPU core than a domain-specific accelerator (and hopefully by then the multi-core stuff in Litex will have sufficiently stabilized that it’d be a relatively low-risk proposition to throw a second CPU into a chip tape-out).
That being said, I learned a lot, and I hope that by sharing my experience, someone else will find Curve25519 a little more approachable, too!
Good article!
An open source implementation of such an algorithm (not targeting RISCV) is available here.
https://trac.cryptech.is/browser/core/pkey/ed25519?order=name
I have used the ecdsa256 and ecdsa384 cores of the cryptech project for a multimode IP implementing ECC point multiplication, and they are a good reference, even though NOT oriented towards a low gate count. However, it would have taken me forever to master the maths to get to a real IP if I started from scratch, so at least they accelerated my work!
I am not sure I get why you needed the rust macro for the assembly… did you use actual 6502 microcontroller opcodes for the microcode ?
When adding ECC 521p curve, I ended up writing a python script to generate microcode in the same format, but I would have liked to use a more clever approach.
See the microcode here.
https://trac.cryptech.is/browser/core/pkey/ecdsa256/rtl/ecdsa256_microcode_rom.v
No, they aren’t actual 6502 opcodes, we just used the format of the macro as a template to generate our machine code! It just so happened someone made a macro assembler for 6502 that was easily adapted to our purpose.
Since propagating carries takes so much time, what if you put that off until after all the multiplies were done? Instead of 15x 17-bit numbers, use 16x 16-bit numbers with the free (17th) bit of each number left to prevent carries from propagating more than once.
All the multiplication would still be 17-bit (since the carry bits are no longer normalized), collapsing partial sums would have the shifts and masks modified for 16 bits, and the new sloppy carry propagation would look like this:
for (int i = 0; i > 15) * 19
} else if (i == 15) {
// 255 doesn’t divide evenly into 16 so this one is only 15 bits
propout[15] = (propin[15] & 0x7fff) + (propin[14] >> 16)
} else {
propout[i] = (propin[i] & 0xffff) + (propin[i-1] >> 16)
}
}
Then do all your multiplication with these sloppy non-normalized numbers and then do one proper carry propagation at the end. Would require more multiplies and larger (272-bit) registers, but would remove most of the carry propagation
Not sure what happened, the form submission seems to have eaten half the code. Here it is in base64:
Zm9yIChpbnQgaSA9IDA7IGkgPCAxNjsgaSsrKSB7CiAgaWYgKGkgPT0gMCkgewogICAgcHJvcG91dFswXSA9IChwcm9waW5bMF0gJiAweGZmZmYpICsgKHByb3BpblsxNV0gPj4gMTUpICogMTkKICB9IGVsc2UgaWYgKGkgPT0gMTUpIHsKICAgIC8vIDI1NSBkb2Vzbid0IGRpdmlkZSBldmVubHkgaW50byAxNiBzbyB0aGlzIG9uZSBpcyBvbmx5IDE1IGJpdHMKICAgIHByb3BvdXRbMTVdID0gKHByb3BpblsxNV0gJiAweDdmZmYpICsgKHByb3BpblsxNF0gPj4gMTYpCiAgfSBlbHNlIHsKICAgIHByb3BvdXRbaV0gPSAocHJvcGluW2ldICYgMHhmZmZmKSArIChwcm9waW5baS0xXSA+PiAxNikKICB9Cn0=
Oh, the code’s there. This blog just allows arbitrary HTML.
alert(‘xss’);
I haven’t finished reading your post, but I think you would enjoy Martin Kleppman’s paper describing in clear details of a fast, constant time ed25519 implementation, which includes a trick to make dealing with carries less painful – you just use bigger limbs and do more computation before you propagate the carries. Not sure how well that would fit into the FPGA constraints, but definitely worth reading the very accessible paper!
https://martin.kleppmann.com/2020/11/18/distributed-systems-and-elliptic-curves.html (see the second half of the post)
Thanks for the write-up, which was an interesting read to me. And you say, that you don’t like to write papers :-)