"Performance where you need it, Convenience when you want it"
Abstract
The Reconfigurable RISC (ReRISC) processor gives users the
opportunity to create application specific instructions for enhanced
performance while providing the programming convenience of a
conventional RISC processor. The core of the ReRISC consists of an
array of 38x8 computational elements, each with 8 configuration
contexts that are selectable on a cycle by cycle basis. The
computational elements default to the MIT Beta ISA upon soft reset,
which reduces redundant reconfiguration cycles. In conjunction with a
reconfigurable NOR plane, the core can be wired to perform a wide
variety of operations, including vector-style packed word operations,
multiply-accumulates, random permutations, tag field verification, and
bit field packing and unpacking. This last feature makes the ReRISC
better suited for the interpretation of nonnative binaries. The
datapath of the 1.8 million transistor ReRISC processor was conceived,
designed, implemented and verified in this design project.
Documentation
ReRISC Project Report for MIT's 6.371 Introduction to VLSI Systems
On-line documentation for the first generation ReRISC prototye.
ReRISC slide presentation
Brain Candy
With the ReRISC, compilers can now analyze programs and determine
the optimal instruction set architecture (ISA) for that particular
program. The code can then be compiled into a binary for that ISA, and
executed on the ReRISC. For example, the code for a JPEG decompressor
would run best on an ISA which supports vector-style operations (MMX),
while the code for an encryption algorithm could take advantage of
powerful bit-manipulation instructions. The ReRISC do both.
The ReRISC is well suited for executing non-native binaries. Its
powerful full-crossbar, 1/2 PLA NOR plane combined with a programmable
masking unit lets the ReRISC extract bitfields out of non-native
instructions in a single cycle.
The full-crossbar NOR plane also makes the ReRISC uniquely suited for
implementing cryptographic algorithms. One can perform the DES P-box in
four cycles, as well as RC-5 data dependent rotations in a single cycle.
The ReRISC architecture may offer better perfomance scaling
than conventional processors with decreasing line geometries. Current
processors run faster at smaller geometries primarily because the
transistors get faster. However, they are unable to efficiently
utilize the huge number of transistors available in cutting edge
processes because of the complexity involved in superscalar and other
parallel architectures; instead, designers are starting to just throw
really large caches on-chip for only a few percent gain in
performance. Because of the ReRISC's array structure, the increased
areal density gained by finer lithography can translate directly into
higher performance. For example, a multiply operation on the
first-generation ReRISC processor takes four clock cycles because it
is only capable of computing 8 partial products simultaneously (the
processor is a 38x8 array). Scaling the array to twice its size allows
one to complete the operation in half the time. This is in addition to
the speedup afforded by the faster transistors.
The ReRISC architecture may provide a good solution for the
hardware support of tagged datatypes. Data tags can assist the
implementation a number of important software abstractions, including
pointer validation, safe datatype management, secure memory
management, garbage collection, atomic semaphores, virtual memory, and
hash tables. Hardware support for tags can significantly boost the
performance of systems which utilize tags, but until now, a change in
the software spec for tags meant buying a new processor. ReRISC gives
programmers the convenience of being able to arbitrarily change tag
definitions without losing the power of hardware support for tags.
The ReRISC architecture allows for the reuse and scaling of
instruction set configurations. The mapping of instruction
definitions into the computational array is independant of many array
parameters, such as the size of the array. Thus, one can upgrade the
ReRISC hardware by adding more computational elements in the array
while maintaining binary-level backward compatibility. One can also
trivially convert scalar instruction definitions into vector
operations by simply replicating the scalar definition across the
width of the vector datapath. This reusability and level of hardware
independance helps encourage the development of instruction set
libraries which people can conveniently share. This enables those of us
who aren't ReRISC architecture wizards to still write zippy
applications.
Acknowledgements Thanks to Ed Kim, my 6.371 class
project partner, for all his hard work on the register file physical
design. Also, a hats off to Andre DeHon for his awesome PhD thesis on
reconfigurable computing. Last but not least, thanks to TK, my advisor
for 6.961 and the smax group, for his guidance and encouragement.

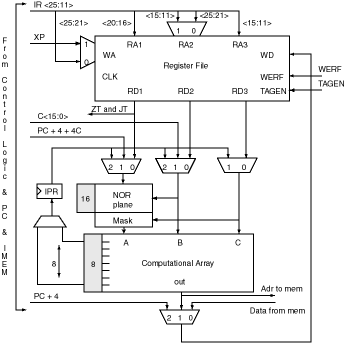
First generation ReRISC prototype:
Block diagram of the ReRISC datapath.
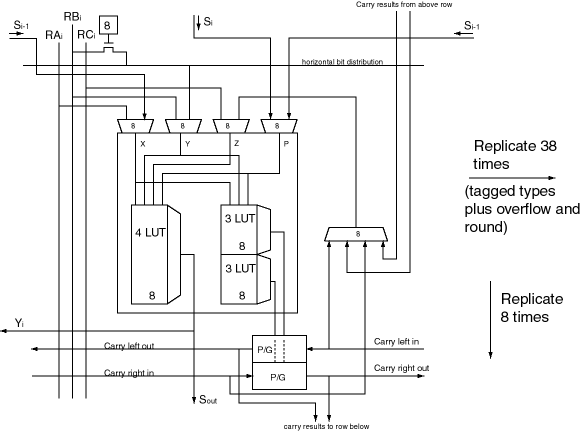
 Block diagram of the ReRISC computational cell.
Block diagram of the ReRISC computational cell.
 Layout shot of a single computational cell.
Layout shot of a single computational cell.
 Berkeley Magic physical design of the first generation ReRISC datapath elements. -- email bunnie@mit.edu for access to files
Berkeley Magic physical design of the first generation ReRISC datapath elements. -- email bunnie@mit.edu for access to files
Ideas for the next generation ReRISC:
The first generation ReRISC prototype was a heavily memory-dominated
design. Future revisions of the ReRISC could do the following to help
utilize silicon area more efficiently:
- Combined register file and crossbar (1/2 NOR plane) units.
The dimensions of the
register file and crossbar arrays are very similar, and many of the wires
share common functions between the two. Combining the RF and the XB would
also yield a faster design.
- Set the ratio of configuration memory blocks to bits of datapath
controlled to 2:1. Currently, the ratio is 1:1, ie, every bit of the
datapath is independantly configurable. A ratio of 2:1 in the
computational array would imply that every 2 bits would have to
perform an identical computation, but for most applications, that is
not a great loss, since the granularity is often as coarse as 8:1. By
setting the ratio to 2:1 we can reduce the memory area by 50%, and
hence reduce the overall area of the computational array by close to
that amount.
- Use a smaller RAM cell for storing the configuration information.
Currently, an 8T SRAM cell design is employed; perhaps by moving to
DRAM, one can significantly reduce the area of the design. The only
catch is designing a low area overhead refresh circuit that never
stalls processor operation in the case that refresh and processing
overlap. One solution might be to include an extra bit in each DRAM
configuration context set which mirrors the information in the bit
being refreshed.
The second generation ReRISC computational array should also
include the computational hardware and connectivity necessary to
efficiently implement floating point operations (especially multiplies
and adds).
Another idea for the second generation ReRISC is to consider
coupling the processor and the memory subsystems more tightly, so as
to insure that the processor has sufficient bandwidth to memory. At
least, the issue of balancing the processor and memory subsystem
should be investigated seriously.
The next gen ReRISC should have a cleaner exception handling spec
to facilitate OS development.
A suggestion for the physical design of the next gen device: lay
out the computational array first, and then pitch-match the combined
register file/crossbar unit to the computational array.
bunnie@mit.edu
Last modified by bunnie@mit.edu Mon May 18 23:56:10 1998
This
page has been accessed at least  times since the counter was last reset, or
May 14, 1998, whichever
is more recent.
times since the counter was last reset, or
May 14, 1998, whichever
is more recent.
home
Copyright (c) 1998, Andrew Huang