“Secure Element” (SE) chips have traditionally taken a very closed-source, NDA-heavy approach. Thus, it piqued my interest when an early-stage SE chip startup, Cramium (still in stealth mode), approached me to advise on open source strategy. This blog post explains my reasoning for agreeing to advise Cramium, and what I hope to accomplish in the future.
As an open source hardware activist, I have been very pleased at the progress made by the eFabless/Google partnership at creating an open-to-the-transistors physical design kit (PDK) for chips. This would be about as open as you can get from the design standpoint. However, the partnership currently supports only lower-complexity designs in the 90nm to 180nm technology nodes. Meanwhile, Cramium is planning to tape out their security chip in the 22nm node. A 22nm chip would be much more capable and cost-effective than one fabricated in 90nm (for reference, the RP2040 is fabricated in 40nm, while the Raspberry Pi 4’s CPU is fabricated in 28nm), but it would not be open-to-the-transistors.
Cramium indicated that they want to push the boundaries on what one can do with open source, within the four corners of the foundry NDAs. Ideally, a security chip would be fabricated in an open-PDK process, but I still feel it’s important to engage and help nudge them in the right direction because there is a genuine possibility that an open SDK (but still closed PDK) SE in a 22nm process could gain a lot of traction. If it’s not done right, it could establish poor de-facto standards, with lasting impacts on the open source ecosystem.
For example, when Cramium approached me, their original thought was to ship the chip with an ARM Cortex M7 CPU. Their reasoning is that developers prize a high-performance CPU, and the M7 is one of the best offerings in its class from that perspective. Who doesn’t love a processor with lots of MHz and a high IPC?
However, if Cramium’s chip were to gain traction and ship to millions of customers, it could effectively entrench the ARM instruction set — and more importantly — quirks such as the Memory Protection Unit (MPU) as the standard for open source SEs. We’ve seen the power of architectural lock-in as the x86 serially shredded the Alpha, Sparc, Itanium and MIPS architectures; so, I worry that every new market embracing ARM as a de-facto standard is also ground lost to fully open architectures such as RISC-V.
So, after some conversations, I accepted an advisory position at Cramium as the Ecosystem Engineer under the condition that they also include a RISC-V core on the chip. This is in addition to the Cortex M7. The good news is that a RISC-V core is royalty-free, and the silicon area necessary to add it at 22nm is basically a rounding error in cost, so it was a relatively easy sell. If I’m successful at integrating the RISC-V core, it will give software developers a choice between ARM and RISC-V.
So why is Cramium leaving the M7 core in? Quite frankly, it’s for risk mitigation. The project will cost upwards of $20 million to tape out. The ARM M7 core has been taped out and shipped in millions of products, and is supported by a billion-dollar company with deep silicon experience. The VexRiscv core that we’re planning to integrate, on the other hand, comes with no warranty of fitness, and it is not as performant as the Cortex M7. It’s just my word and sweat of brow that will ensure it hopefully works well enough to be usable. Thus, I find it understandable that the people writing the checks want a “plan B” that involves a battle-tested core, even if proprietary.
This will understandably ruffle the feathers of the open source purists who will only certify hardware as “Free” if and only if it contains solely libre components. I also sympathize with their position; however, our choices are either the open source community somehow provides a CPU core with a warranty of fitness, effectively underwriting a $20 million bill if there is a fatal bug in the core, or I walk away from the project for “not being libre enough”, and allow ARM to take the possibly soon-to-be-huge open source SE market without challenge.
In my view it’s better to compromise and have a seat at the table now, than to walk away from negotiations and simply cede green fields to proprietary technologies, hoping to retake lost ground only after the community has achieved consensus around a robust full-stack open source SE solution. So, instead of investing time arguing over politics before any work is done, I’m choosing to invest time building validation test suites. Once I have a solid suite of tests in hand, I’ll have a much stronger position to argue for the removal of any proprietary CPU cores.
On the Limit of Openness in a Proprietary Ecosystem
Advising on the CPU core is just one of many tasks ahead of me as their open source Ecosystem Engineer. Cramium’s background comes from the traditional chip world, where NDAs are the norm and open source is an exotic and potentially fatal novelty. Fatal, because most startups in this space exit through acquisition, and it’s much harder to negotiate a high acquisition price if prized IP is already available free-of-charge. Thus my goal is to not alienate their team with contumelious condescension about the obviousness and goodness of open source that is regrettably the cultural norm of our community. Instead, I am building bridges and reaching across the aisle, trying to understand their concerns, and explaining to them how and why open source can practically benefit a security chip.
To that end, trying to figure out where to draw the line for openness is a challenge. The crux of the situation is that the perceived fear/uncertainty/doubt (FUD) around a particular attack surface tends to have an inverse relation to the actual size of the attack surface. This illustrates the perceived FUD around a given layer of the security hierarchy:
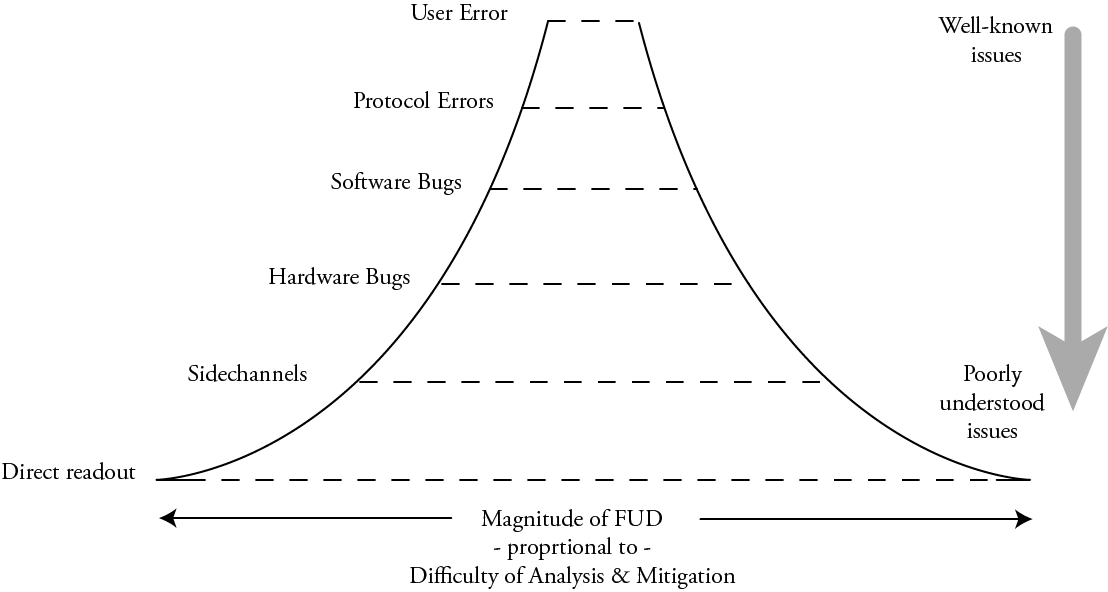
Generally, the amount of FUD around an attack surface grows with how poorly understood the attack surface is: naturally we fear things we don’t understand well; likewise we have less fear of the familiar. Thus, “user error” doesn’t sound particularly scary, but “direct readout” with a focused ion beam of hardware security keys sounds downright leet and scary, the stuff of state actors and APTs, and also of factoids spouted over beers with peers to sound smart.
However, the actual size of the attack surface is quite the opposite:
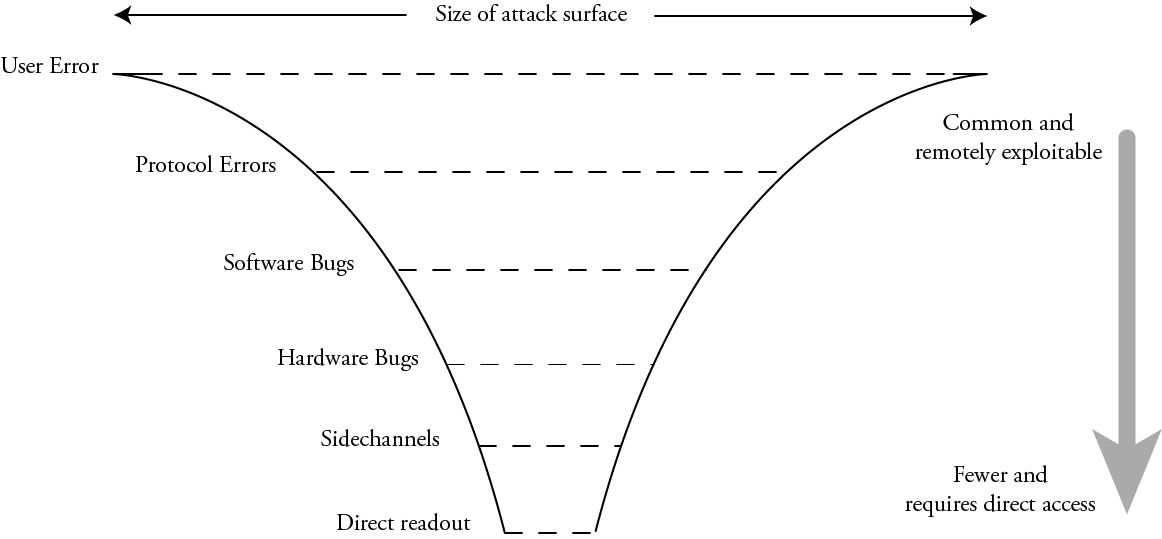
In practice, “user error” – weak passwords, spearphishing, typosquatting, or straight-up fat fingering a poorly designed UX – is common and often remotely exploitable. Protocol errors – downgrade attacks, failures to check signatures, TOCTOUs – are likewise fairly common and remotely exploitable. Next in the order are just straight-up software bugs – buffer overruns, use after frees, and other logic bugs. Due to the sheer volume of code (and more significantly the rate of code turnover) involved in most security protocols, there are a lot of bugs, and a constant stream of newly minted bugs with each update.
Beneath this are the hardware bugs. These are logical errors in the implementation of a function of a piece of hardware, such as memory aliasing, open test access ports, and oversights such as partially mutable cryptographic material (such as an AES key that can’t be read out, but can be updated one byte at a time). Underneath logical hardware bugs are sidechannels – leakage of secret information through timing, power, and electromagnetic emissions that can occur even if the hardware is logically perfect. And finally, at the bottom layer is direct readout – someone with physical access to a chip directly inspecting its arrangement of atoms to read out secrets. While there is ultimately no defense against the direct readout of nonvolatile secrets short of zeroizing them on tamper detection, it’s an attack surface that is literally measured in microns and it requires unmitigated physical access to hardware – a far cry from the ubiquity of “user error” or even “software bugs”.
The current NDA-heavy status quo for SE chips creates an analytical barrier that prevents everyday users like us from determining how big the actual attack surface is. That analytical barrier actually extends slightly up the stack from hardware, into “software bugs”. This is because without intimate knowledge of how the hardware is supposed to function, there are important classes of software bugs we can’t analyze.
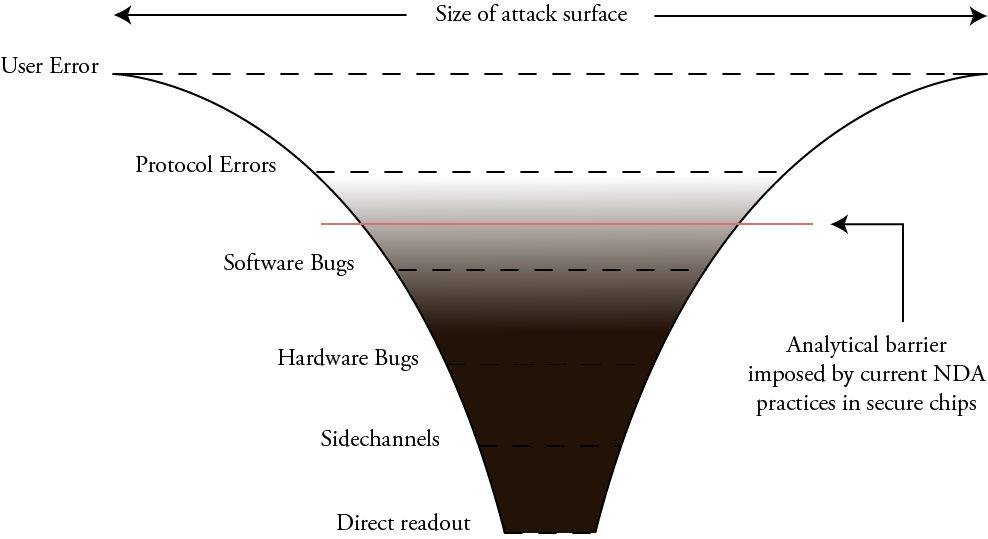
Furthermore, the inability of developers to freely write code and run it directly on SEs forces more functionality up into the protocol layer, creating an even larger attack surface.
My hope is that working with Cramium will improve this situation. In the end, we won’t be able to entirely remove all analytical barriers, but hopefully we arrive at something closer to this:
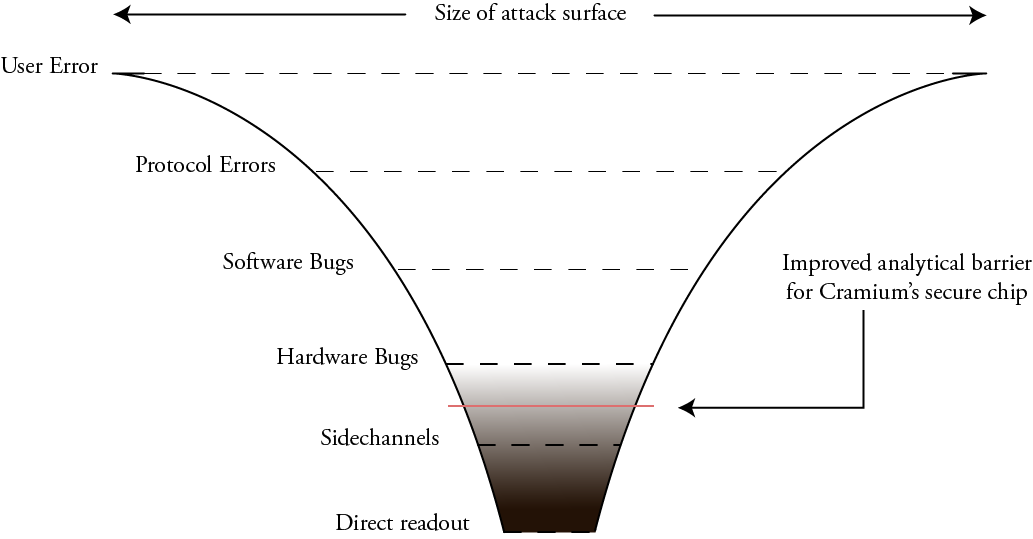
Due to various NDAs, we won’t be able to release things such as the mask geometries, and there are some blocks less relevant to security such as the ADC and USB PHY that are proprietary. However, the goal is to have the critical sections responsible for the security logic, such as the cryptographic accelerators, the RISC-V CPU core, and other related blocks shared as open source RTL descriptions. This will allow us to have improved, although not perfect, visibility into a significant class of hardware bugs.
The biggest red flag in the overall scenario is that the on-chip interconnect matrix is slated to be a core generated using the ARM NIC-400 IP generator, so this logic will not be available for inspection. The reasoning behind this is, once again, risk mitigation of the tapeout. This is unfortunate, but this also means we just need to be a bit more clever about how we structure the open source blocks so that we have a toolbox to guard against potential misbehavior in the interconnect matrix.
My personal goal is to create a fully OSS-friendly FPGA model of the RISC-V core and their cryptographic accelerators using the LiteX framework, so that researchers and analysts can use this to model the behavior of the SE and create a battery of tests and fuzzers to confirm the correctness of construction of the rest of the chip.
In addition to the work advising Cramium’s engagement with the open source community, I’m also starting to look into non-destructive optical inspection techniques to verify chips in earnest, thanks to a grant I received from NLNet’s NGI0 Entrust fund. More on this later, but it’s my hope that I can find a synergy between the work I’m doing at Cramium and my silicon verification work to help narrow the remaining gaps in the trust model, despite refractory foundry and IP NDAs.
Counterpoint: The Utility of Secrecy in Security
Secrecy has utility in security. After all, every SE vendor runs with this approach, and for example, we trust the security of nuclear stockpiles to hardware that is presumably entirely closed source.
Secrecy makes a lot of sense when:
- Even a small delay in discovering a secret can be a matter of life or death
- Distribution and access to hardware is already strictly controlled
- The secrets would rather be deleted than discovered
Military applications check all these boxes. The additional days, weeks or months delay incurred by an adversary analyzing around some obfuscation can be a critical tactical advantage in a hot war. Furthermore, military hardware has controlled distribution; every mission-critical box can be serialized and tracked. Although systems are designed assuming serial number 1 is delivered to the Kremlin, great efforts are still taken to ensure that is not the case (or that a decoy unit is delivered), since even a small delay or confusion can yield a tactical advantage. And finally, in many cases for military hardware, one would rather have the device self-destruct and wipe all of its secrets, rather than have its secrets extracted. Building in booby traps that wipe secrets can measurably raise the bar for any adversary contemplating a direct-readout attack.
On the other hand, SEs like those found in bank cards and phones are:
- Widely distributed – often directly and intentionally to potentially adversarial parties
- Protecting data at rest (value of secret is constant or may even grow with time)
- Used as a trust root for complicated protocols that typically update over time
- Protecting secrets where extraction is preferable to self-destruction. The legal system offers remedies for recourse and recovery of stolen assets; whereas self-destruction of the assets offers no recourse
In this case, the role of the anti-tamper countermeasures and side-channel minimization is to raise the investment necessary to recover data from “trivial” to somewhere around “there’s probably an easier and cheaper way to go about this…right?”. After all, for most complicated cryptosystems, the bigger risk is an algorithmic or protocol flaw that can be exploited without any circumvention of hardware countermeasures. If there is a protocol flaw, employing an SE to protect your data is like using a vault, but leaving the keys dangling on a hook next to the vault.
It is useful to contemplate who bears the greatest risk in the traditional SE model, where chips are typically distributed without any way to update their firmware. While an individual user may lose the contents of their bank account, a chip maker may bear a risk of many tens of millions of dollars in losses from recalls, replacement costs and legal damages if a flaw were traced to their design issue. In this game, the player with the most to lose is the chipmaker, not any individual user protected by the chip. Thus, a chipmaker has little incentive to disclose their design’s details.
A key difference between a traditional SE and Cramium’s is that Cramium’s firmware can be updated (assuming an updateable SKU is released; this was a surprisingly controversial suggestion when I brought it up). This is thanks in part to the extensive use of non-volatile ReRAM to store the firmware. This likewise shifts the calculus on what constitutes a recall event. The open source firmware model also means that the code on the device comes, per letter of the license, without warranty; the end customer is ultimately responsible for building, certifying and deploying their own applications. Thus, for a player like Cramium, the potential benefits of openness outweigh those of secrecy and obfuscation embraced by traditional SE vendors.
Summary
My role is to advise Cramium on how to shift the norms around SEs from NDAs to openness. Cramium is not attempting to forge an open-foundry model – they are producing parts using a relatively advanced (compared to your typical stand-alone SE) 22nm process. This process is protected by the highly restrictive foundry NDAs. However, Cramium plans to release much of their design under an open source license, to achieve the following goals:
- Facilitate white-box inspection of cryptosystems implemented using their primitives
- Speed up discovery of errors; and perhaps more importantly, improve the rate at which they are patched
- Reduce the risk of protocol and algorithmic errors, so that hardware countermeasures could be the actual true path of least resistance
- Build trust
- Promote wide adoption and accelerate application development
Cramium is neither fully open hardware, nor is it fully closed. My goal is to steer it toward the more open side of the spectrum, but the reality is there are going to be elements that are too difficult to open source in the first generation of the chip.
The Cramium chip complements the eFabless/Google efforts to build open-to-the-transistors chips. Today, one can build chips that are open to the mask level using 90 – 180nm processes. Unfortunately, the level of integration achievable with their current technology isn’t quite sufficient for a single-chip Secure Element. There isn’t enough ROM or RAM available to hold the entire application stack on chip, thus requiring a multi-chip solution and negating the HSM-like benefits of custom silicon. The performance of older processes is also not sufficient for the latest cryptographic systems, such as Post Quantum algorithms or Multiparty Threshold ECDSA with Identifiable Aborts. On the upside, one could understand the design down to the transistor level using this process.
However, it’s important to remember that knowing the mask pattern does not mean you’ve solved the supply chain problem, and can trust the silicon in your hands. There are a lot of steps that silicon goes through to go from foundry to product, and at any of those steps the chip you thought you’re getting could be swapped out with a different one; this is particularly easy given the fact that all of the chips available through eFabless/Google’s process use a standardized package and pinout.
In the context of Cramium, I’m primarily concerned about the correctness of the RTL used to generate the chip, and the software that runs on it. Thus, my focus in guiding Cramium is to open sufficient portions of the design such that anyone can analyze the RTL for errors and weaknesses, and less on mitigating supply-chain level attacks.
That being said, RTL-level transparency can still benefit efforts to close the supply chain gap. A trivial example would be using the RTL to fuzz blocks with garbage in simulation; any differences in measured hardware behavior versus simulated behavior could point to extra or hidden logic pathways added to the design. Extra backdoor circuitry injected into the chip would also add loading to internal nodes, impacting timing closure. Thus, we could also do non-destructive, in-situ experiments such as overclocking functional blocks to the point where they fail; with the help of the RTL we can determine the expected critical path and compare it against the observed failure modes. Strong outliers could indicate tampering with the design. While analysis like this cannot guarantee the absence of foundry-injected backdoors, it constrains the things one could do without being detected. Thus, the availability of design source opens up new avenues for verifying correctness and trustability in a way that would be much more difficult, if not impossible, to do without design source.
Finally, by opening as much of the chip as possible to programmers and developers, I’m hoping that we can get the open source SE chip ecosystem off on the right foot. This way, as more advance nodes shift toward open PDKs, we’ll be ready and waiting to create a full-stack open source solution that adequately addresses all the security needs of our modern technology ecosystem.
I’m a bit sad that people are jumping for the “shiny new” instead of thinking hard about whether a secure element *really needs* an advanced process. The whole point of this chip is that it’s in a space where trust matters more than performance. Sacrificing performance to get trust seems like something you would want to do.
> one can build chips that are open to the mask level using 90 – 180nm processes. … isn’t quite sufficient for a single-chip Secure Element. There isn’t enough ROM or RAM available to hold the entire application stack on chip
That’s only true if you are limited to the tiny user area on eFabless’s “freebie” runs. The full reticle on typical 180nm processes is about 83x that size (33mm*26mm vs 2.92mm*3.52mm). Sure, you have to buy a full maskset in order to get that much space, but for a 180nm process that costs less than $90k. Think about how many shots at the goal you could take for that price…
If your plan succeeds, you’ll provide a way for people to be sure that M7 “zombie core” can’t be resurrected, right? Come to think of it, I’m not sure how you would do that in a way that could be verified electrically. Maybe bring the welltaps for that core out to a separate analog pad (this sort of connection can be verified externally — forward voltage drop and resistance when unpowered should be hard to fake), and then provide a way to monkey with that bias in a way that makes the M7 unusable without causing latchup. I’m assuming this is bulk CMOS, but weren’t most of the 22nm processes FDSOI? If so, probably even more interesting options.
It comes down to economics and yield. I’ve considered doing a large-reticle SE at a larger node to integrate the memory necessary to implement the required applications, but the unit price goes up with the silicon area. 22nm (and 28nm) turns out to be the “sweet spot” for cost/transistor, if you can get over the up-front mask costs.
So it’s not a “shiny/new” issue — it’s that if you have one chip that does ostensibly the same thing as the other but it costs less than 1/10th as much while doing the same thing, one of them will dominate the market; and perhaps more significantly, enable markets that would be otherwise inaccessible with a more expensive solution.
> you have one chip that does ostensibly the same thing as the other
For a secure element, if one of them has an auditable layout and the other doesn’t, then they aren’t *really* doing the same thing…
For some users, this is a true statement. However, going full-reticle to achieve the same thing as a smaller process node scales cost up by roughly the silicon area. So as a thought experiment, let’s imagine a nearly full-reticle security chip going for say, 40x the price of one taped out in a more advance node.
Getting people to care about a fully-auditable layout enough to pay 40x the price is a hard sell: one product going for \$5 that has a “mostly-verifiable” design (down to the RTL, but not to the transistors) will sell a lot more units than one going for \$200 that is fully verifiable down to the transistor layout. Especially if the \$5 unit consumes less power and runs faster because of the non-cost benefits of running in a smaller node.
Alternatively, if the *only* remotely auditable product on offer is the \$200 version that is fully-verifiable, but consumes more power, runs slower, and is physically larger than a \$5 completely closed solution, I’d wager that 99.99% of users will still prefer to buy the \$5 version, so long as it comes from a “reputable” company. In practice the end result is you’d go out of business the moment someone pushed a mostly-verifiable design offered at \$5.
A fundamental problem is that the supply chain security gap is still very abstract to most users, but operating costs are very real. So you’re correct there is a difference between auditable-to-the-transistors and auditable-to-the-RTL; but I’m not sure the market perceives that difference as significant.
However, if you can figure out a way to convince a majority of everyday users to pay the appropriate premium for fully auditable hardware fabricated using a full reticle in older design nodes, despite the penalty in cost, power, and performance, I’m all ears!
I don’t understand the application for this new SE. It’s a single chip module because MCMs are less secure (with an open bus for probing), but for secure boot, this chip will probably be paired with a large Application Processor via its external bus. So it will still have an exposed bus between those two chips.
You’d need an encrypted/authenticated channel between chips, so there would be a custom IP block added to each chip that relies on the Cramium SE?
Boot security isn’t the only application for SEs. Captive keys in general are a useful market. See smartcards, and existing SEs like the Atmel ATECC line.
(The ATECC line to my recollection does also advertise use for the ‘secure boot’, which I find nonsensical for the reasons you give.)
There’s no reason a secure channel to the SE can’t be implemented on the host CPU; the main issue is whether the host has exclusive access to any secret which allows it to authenticate itself to the SE, which it generally doesn’t. Whether this matters depends on whether you want to do trusted computing-like things with your threat model.
[…] Read much more in Bunnie’s post here. […]
How are you approaching the security risk you’re introducing by having two cores, and presumably a supporting system architecture that can be configured to have either as the primary and the other turned off (or held in reset or whatever)? My limited experience with SE design is there is a lot of peripheral complexity around managing configuration, debug access, OTP/NV bits and state machines to do early configuration before the CPU boots (notably including which CPU to boot), etc. Getting all of that right is hard enough, but in addition you also want it to be as small and simple as possible (so e.g. it doesn’t become a juicy target to fault inject).
Trying to keep it as simple as possible. Still in planning phase, but the nominal idea is to have the reset and/or core clock signal gates wired to ‘fuses’ (actually ReRAM bits with a write-protect bit) that simply cut the core out of the loop if you don’t want to use it. A lot of this could be fused at wafer sort; and all the “OTP” is actually ReRAM so we only need one common programming mechanism to function in order to configure/burn all the pre-boot bits, and ReRAM is more forgiving to work with than OTP.
You’re right that the fuses that would trim out a core could be come juicy targets for fault injection, but simply flipping a bit on the unused core’s hard reset isn’t enough, you’d also have to inject payload code to have the core do something useful to the attackers (and if you have an arbitrary-write primitive to sensitive portions of memory I think you already have big problems); and this all has to happen without triggering any of the active fault detection circuitry. So it might be relatively easy to DoS the system by getting an unused core into a weird state, but it should be harder to get it to do something useful.
How does your PE compare to https://siliconangle.com/2022/10/18/open-compute-project-announces-caliptra-new-standard-hardware-root-trust/
?
You mention “I’m also starting to look into non-destructive optical inspection techniques to verify chips in earnest”, would you be willing to elaborate what is planned here? I’ve worked on destructive RE for a while, and would love to know what non-destructive methods might be usable here, and what they can achieve when it comes to ICs.
The basic line of inquiry relies on backside optical inspection with 1330nm light. You won’t be able to make out individual transistors with the technique, but we should be able to at least resolve that blobs of logic and memory have the expected dimensions. This would rule out a significant class of supply chain attacks.
Are there any licensing restrictions (from the ARM side) about what can be on a chip that has an ARM core? Like the types of other cores, or the applications? I’ve been asked about this issue regarding high end ARM cores, not specifically M-class, so it might be different.
I personally am not reviewing the ARM licensing agreement, but the plan cleared at least some legal review. I presume I would have heard of a show stopper from counsel if they found one.
What are the restrictions on mix/match for high end ARM cores, that you’ve encountered?
“… red flag in the overall scenario is that the on-chip interconnect matrix is slated to be a core generated using the ARM NIC-400 IP generator…”
Indeed, red flag. The one chip project I consulted on that was a 100% functional failure (years ago) failed because of the inscrutable closed RTL bus matrix. The company management decided to exit their intended target market, having missed a critical product deadline and therefore end user product generation.
When do you anticipate this device might be available to the general public? I have a secure crypto-signature device product in my future I do believe. Also – do you think there is any class of fpgas that could be considered “secure” in terms of no hidden manufacturer exploits and a locked in IP that can’t be altered once programmed?
Can’t comment on availability — that’s way above my paygrade. You can watch my alt-github repo (https://github.com/buncram) and infer progress from there, but take it with a grain of salt. My terms of work are strictly open source, but there’s a fairly big and opaque pachinko machine all this has to go through before a chip pops out.
Re: hidden mfg exploits/locked in IP. I think the honest answer is “nobody knows”. You can only know of hidden exploits if you find them, and a lack of reported hidden exploits is more typically the result of a lack of looking, than proof of security. I have heard good things about the PolarFire SoC; you’ll note the product page promotes its applicability for military hardware. Depending on your threat model and your politics it could be a plus or a minus. The most publicly investigated FPGA series is the 7-series FPGA from Xilinx; researchers have torn down its configuration state machines to the gate level and found mistakes but so far I have not heard of something resembling a “secret knock” back door or something like that (but: there is a footgun in the ICAP block which is a deliberate backdoor you as the designer are allowed to instantiate, primarily for partial reconfiguration and debugging purposes. It’s not a bad thing, just something to pay attention to.).
However, one chip is just one chip. Just because one chip looks clear does not mean that the next run is identical, or that the next model doesn’t bake something interesting into the silicon. That’s just how it goes in hardware.
[…] Article Source […]
Hey, are you familiar with TropicSquare ( https://tropicsquare.com/ )? They’re working on something similar. Maybe there’s room to collaborate.
Is Riscv better in terms of security and privsep?