Note: This post originally appeared as an update in the crowdfunding campaign for Precursor.
Modern gadgets are typically built around a single, highly integrated chip, known as a “System on Chip” (SoC). While the earliest home computer motherboards consisted of around a hundred chips, Moore’s Law pushed that down to just a handful of chips by the time 80286 PC/AT clones were mainstream, and the industry has never looked back. Now, a typical SoC integrates a CPU core complex, plus dozens of peripherals, including analog, RF, and power functions; there are even “System in Package” solutions available that package the SoC, RAM, and sometimes even the FLASH die into a single plastic package.
Modern SoCs are exceedingly complex. The “full user’s manual” for a modern SoC is thousands of pages long, and the errata (“bug list”) – if you’re allowed to see it – can be hundreds of pages alone. I put “full user’s manual” in quotations because even the most open, well-documented SoCs (such as the i.MX series from NXP) require a strict NDA to access thousands of pages of documentation on third party Intellectual Property (IP) blocks for functions such as video decoding, graphics acceleration, and security. Beyond the NDA blocks, there is typically a deeper layer of completely unpublished documentation for disused silicon, such as peripherals that were designed-in but did not make the final cut, internal debugging facilities, and pre-boot facilities. Many of these disused features aren’t even well-known within the team that designed the chip!
Disused silicon is a thing because building chips is less like snapping together Legos, and more like a sculptor chiseling away at a marble block: adding a circuit is much harder than deactivating a circuit. Adding a circuit might cost around $1 million in new masks, while delaying the project by about 70 days (at a cost of 100,000 man-hours worth of additional wages); with proper planning, deactivating a circuit may be as simple as a code change, or a small edit to a single mask layer, at a cost of perhaps $10,000 and a few days (assuming wafers were held at intermediate stages to facilitate this style of edit).

photo credit: “Man With Mallet & Chisel Bas Relief (Washington, DC)” by takomabibelot is licensed under CC BY 2.0
Thus a typical SoC mask set starts with lots of extra features, spare logic, and debug facilities that are chiseled away (disused) until the final shape of the SoC emerges. As Michelangelo once said “every block of stone has a statue inside it, and it is the task of the sculptor to discover it,” we could say “every SoC mask set has a datasheet inside it, and it is the task of the validation team to discover it”. Sometimes the final chisel blow happens at boot: an errant feature may be turned off or patched over by pre-boot code that runs even before the CPU executes its first instruction. As a result, even the best documented SoCs will have a non-trivial fraction of transistors that are disused and unaccountable, theoretically invisible to end users.
From a security standpoint, the presence of such “dark matter” in SoCs is worrisome. Forget worrying about the boot ROM or CPU microcode – the BIST (Built in Self Test) infrastructure has everything you need to do code injection, if you can just cajole it into the right mode. Furthermore, SoC integrators all buy functional blocks such as DDR, PCI, and USB from a tiny set of IP vendors. This means the same disused logic motifs are baked into hundreds of millions of devices, even across competing brands and dissimilar product lines. Herein lies a hazard for an unpatchable, ecosystem-shattering security break!
Precursor sidesteps this hazard by implementing its SoC using an FPGA. FPGAs are user-reconfigurable, drastically changing the calculus on the cost of design errors; instead of chiseling away at a block of marble, we are once again building with a Lego set. Of course, this flexibility comes at a cost: an FPGA is perhaps 50x more expensive than a feature-equivalent SoC and about 5-10x slower in absolute MHz. However, it does mean there is no dark matter in Precursor, as every line of code used to describe the SoC is visible for inspection. It also means if logic bugs are found in the Precursor SoC, they can be patched with an update. This drastically reduces the cost to iterate the SoC, making it more economically compatible with an open source approach. In an ideal world, the Precursor SoC design will be thoroughly vetted and audited over the next couple of years, converging on a low-risk path toward a tape out in fixed silicon that can reduce production costs and improve performance all while maintaining a high standard of transparency.
LiteX: The Framework Behind Precursor’s SoC
Precursor’s SoC is built using LiteX. LiteX is a framework created by Florent Kermarrec for defining SoCs using the Migen/MiSoC FHDL, which itself is written in Python 3.6+. The heart of LiteX is a set of “handlers” that will automatically adapt between bus standards and widths. This allows designers to easily mix and match various controllers and peripherals with Wishbone, AXI, and CSR, bus interconnect standards. It is pretty magical to be able to glue an extra USB debug controller into a complex SoC with just a few lines of code, and have an entire infrastructure of bus arbiters and adapters figure themselves out automatically in response. If you want to learn more about LiteX and FPGAs, a great place to start is Florent’s “FPGA_101” mini-course.
A Brief Tour of Precursor’s SoC
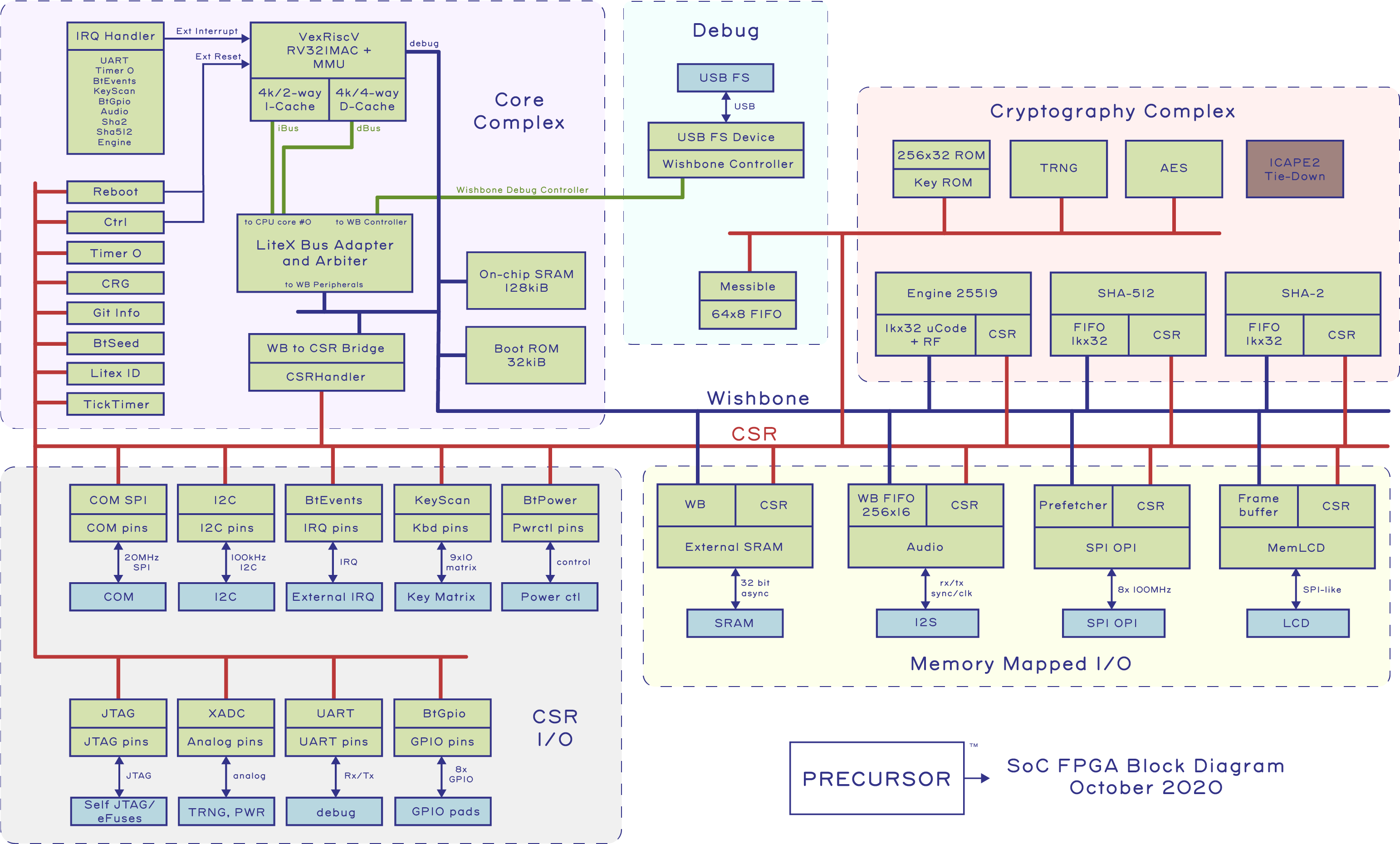
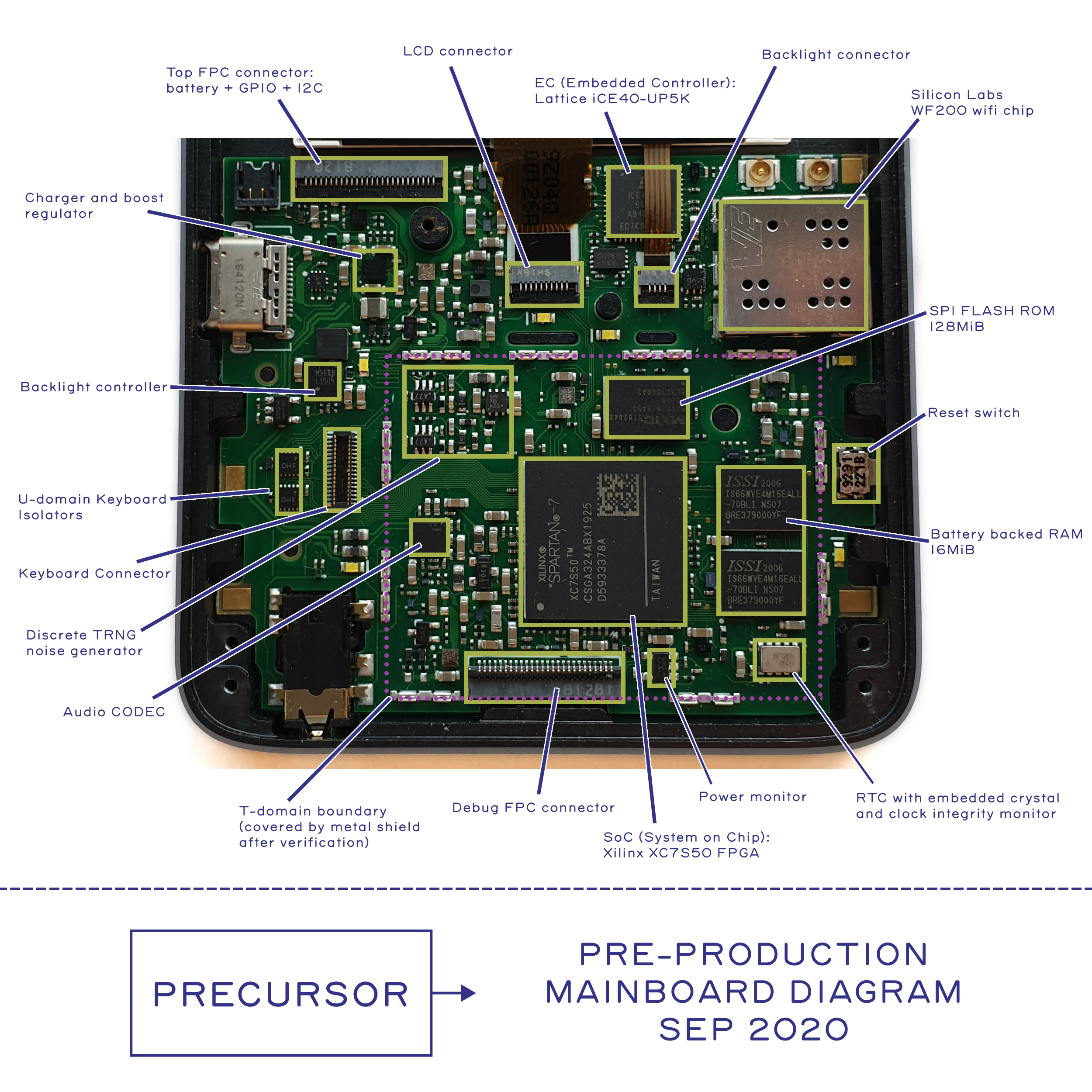
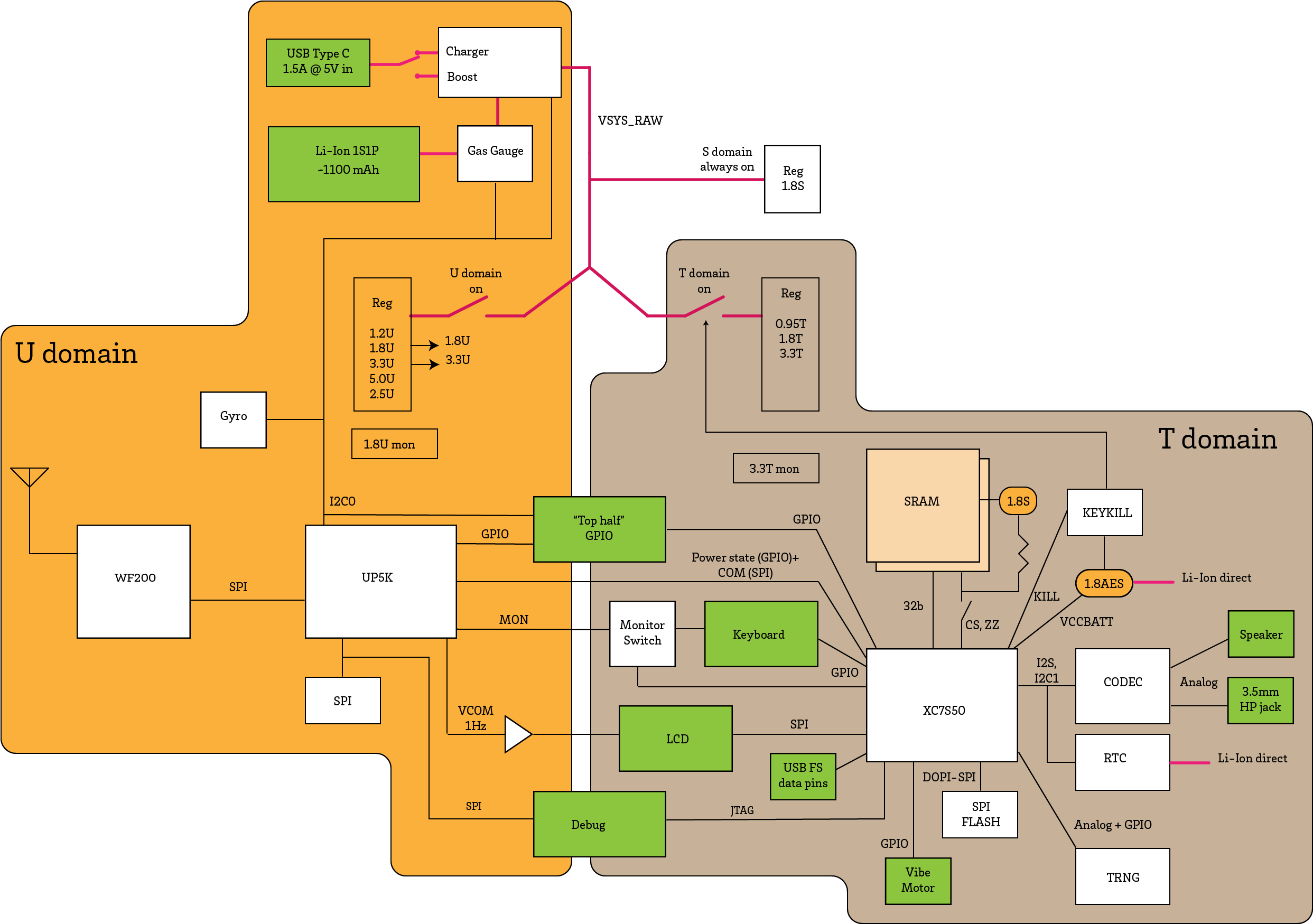
Above is a block diagram of Precursor’s SoC, as of October 2020. It’s important to pay attention to the date on documentation, because an FPGA-based SoC can and will change over time. We generally eschew pretty, hand-drawn block diagrams like this because they are out of date almost the day they are finished. Instead, our equivalent of a “programmer’s manual” is dynamically generated by our CI system with every code push, and for Rust programmers we have a tool, svd2utra that automatically translates SVD files generated by LiteX into a Rust API crate. With an open source FPGA-based SoC, automated CI isn’t merely best practice, it’s essential, because small but sometimes important patches in submodule dependencies will regularly affect your design.
Core Complex
The “Core Complex” currently consists of one RISC-V core, implemented using Charles Papon’s VexRiscV. We configured it to support the “RV32IMAC” instruction subset, gave it an MMU, and beefed up the caches. The VexRiscV limits cache size to 4kiB, but effective capacity can be increased by upping the cache associativity. We get about a 10% performance boost by tuning the core to have a two-way I-cache, and a four-way D-cache. We also provision a 32 kiB boot ROM, which currently holds three instructions, but will someday be expanded to include signature checks on code loaded from external memory and a 128kiB on-board SRAM for tightly coupled/higher security operations. The CPU core is adapted to, and arbitrated into, a multi-controller Wishbone bus by LiteX and further adapted into a CSR bus by a dedicated CSR bridge that has been configured to automatically space peripherals on 4-kiB page boundaries, so that they can be individually remapped with the MMU. There’s also an IRQ handler that manages interrupts originating from peripherals sprinkled around the chip.
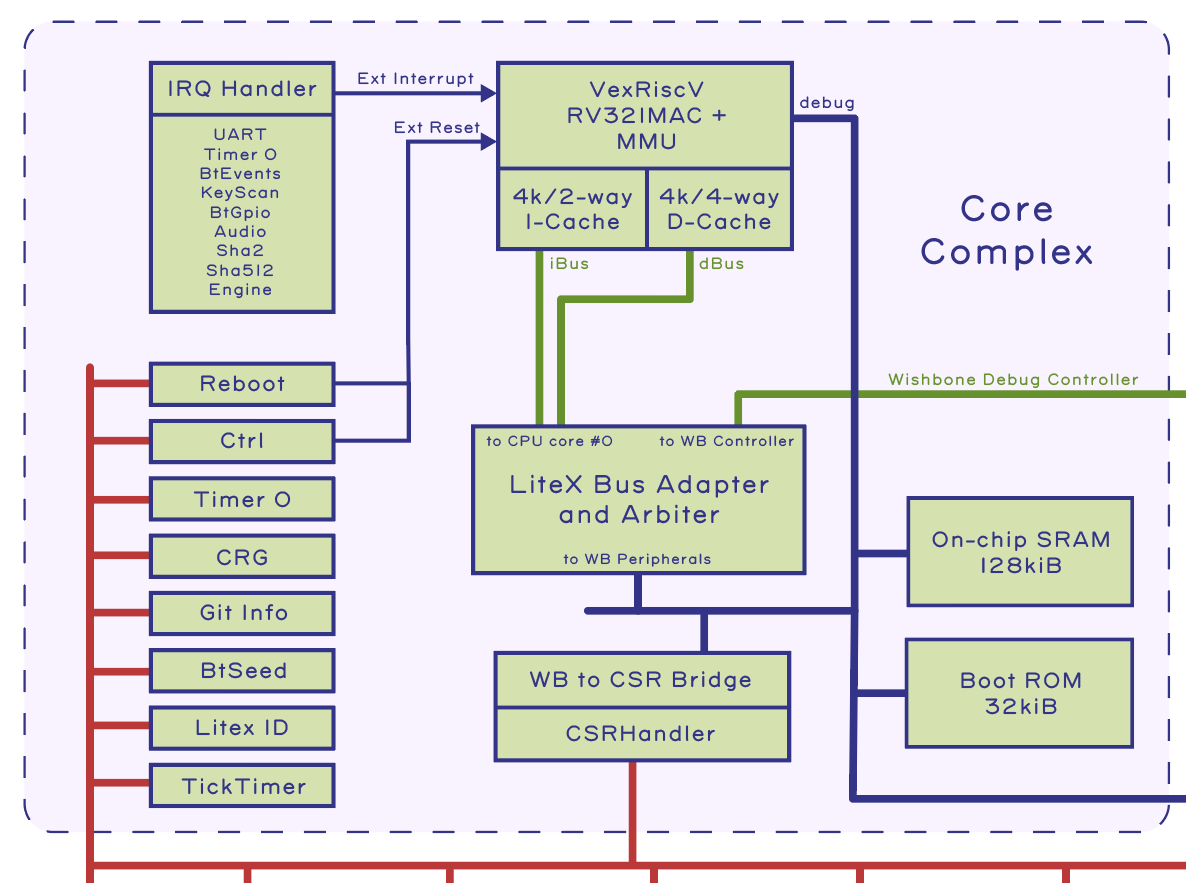
The Core Complex also includes a set of mostly boilerplate CSRs which perform the following functions:
- “Reboot” allows us to specify a new location for the reset vector
- “Ctrl” allows us to issue a soft reset
- “Timer 0” is the default timer provided by LiteX. It is a high resolution 32-bit timer clocked at the same frequency as the CPU core.
- “CRG” is an interface to control the FPGA’s clock generator. Right now we don’t do much with it, but eventually this is going to play a central role in power management and extending battery life.
- “Git Info” is a static register that provides information about the state of the git repo from which Precursor was built.
- “BtSeed” is a 64-bit number that can be randomized to force entropy into the place-and-route process, in case the end user desires a final FPGA netlist unique to their device without having to modify the code (otherwise the builds are entirely reproducible).
- “Litex ID” is a human-readable text string that identifies the SoC design.
- “TickTimer” is a low-resolution, 64-bit timer clocked in 1 ms increments. It serves as a source of time for the Xous OS.
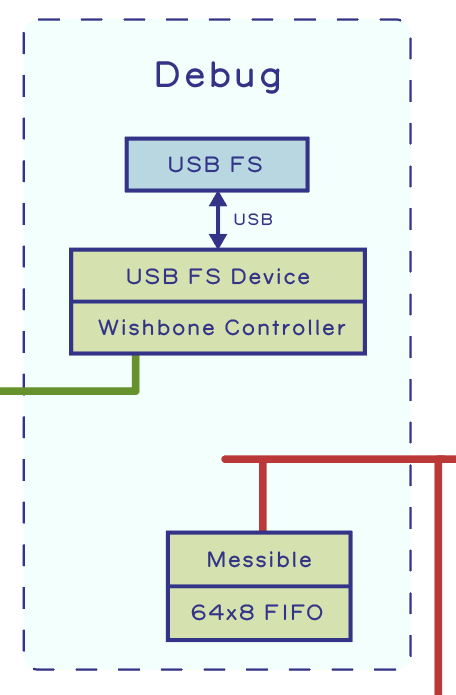
Debug Block
Adjacent to the Core Complex is a Debug block. The Debug block features a full speed USB MAC/PHY that can tunnel Wishbone packets and serve as an alternate Wishbone controller to the CPU. We use this to drive the debug interface on the CPU, thus allowing GDB to connect to Precursor over USB even when the CPU is halted. In fact, one could build Precursor with no RISC-V CPU and just tunnel Wishbone packets over USB for debug and driver development. The debug block also includes a small CSR peripheral called the “Messible”, which is a 64-entry by 8-bit wide FIFO, useful as a mailbox/scratchpad during debugging.
Memory Mapped and CSR I/O
The memory space of the RISC-V CPU is mapped onto various peripherals and memory blocks via a Wishbone bus. For traditional SoC designers, Wishbone is kind of like AXI, but open source. Wishbone supports fancy features like multiple masters, pipelining, and block transfers. A portion of the Wishbone bus space is further mapped onto a bus called the Configuration and Status Register (CSR) bus.
While Wishbone is high-performance, it requires more interface logic and is happiest when the peripheral’s bit width matches the bus width. CSRs are area-efficient and gracefully accommodates registers of arbitrary bit-width from both a hardware and software API standpoint, but are lower performance. Thus CSRs are ideal for low-to-medium speed I/O tasks (such as the eponymous configuration and status registers), whereas Wishbone is ideal for memory-mapped I/O where improved bandwidth and latency are worth the area overhead.
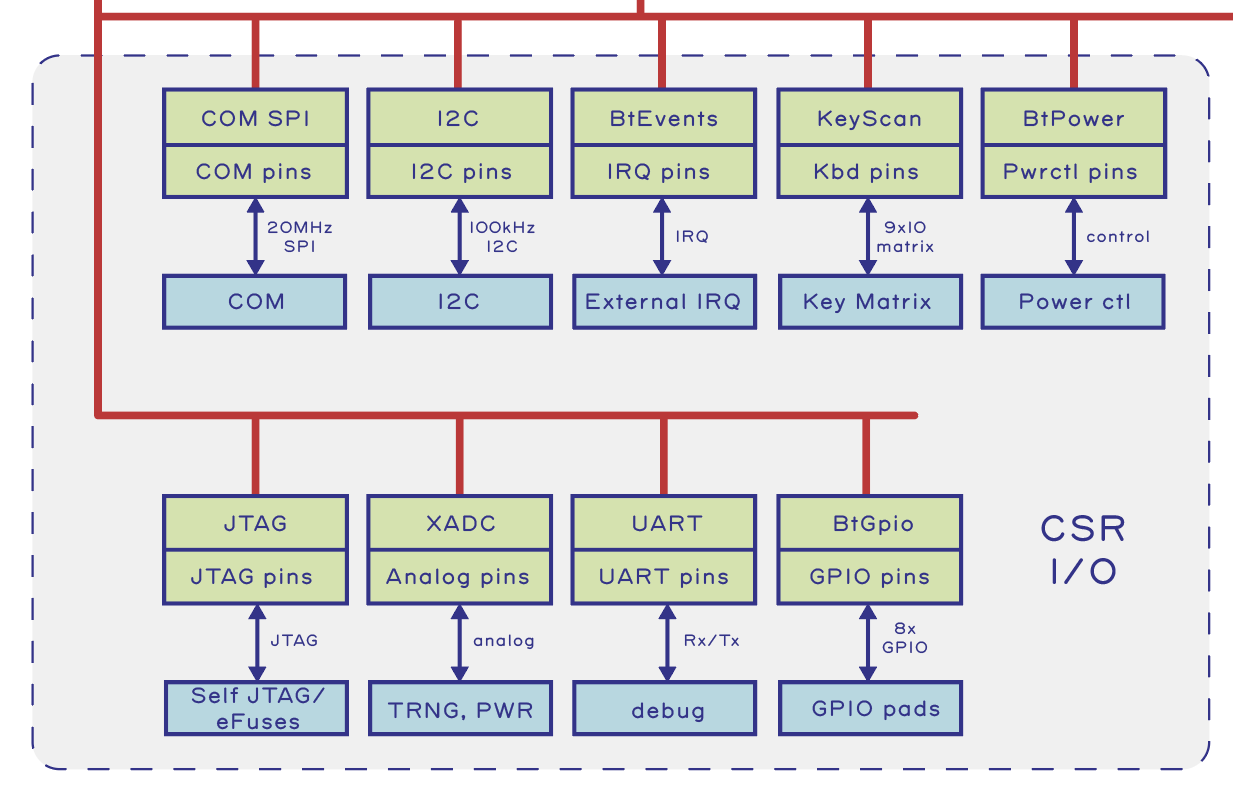
From a design process, most peripherals start life mapped to CSR space, and are then upgraded to a memory-mapped implementation to meet performance demands. Thus, it’s no coincidence that most peripherals on Precursor are CSR-only devices. Here is a brief description of each CSR peripheral. As a reminder, you can always consult our reference manual for more details.
- “COM SPI” is the SPI bus that connects to the Embedded Controller (EC) SoC. It’s a 20MHz SPI peripheral that has a fixed transfer width of 16-bits. This block is targeted for an upgrade to a memory mapped I/O block.
- “I2C” is an I2C bus controller. Currently, only a real time clock (RTC) chip and an audio CODEC chip are are connected to this I2C bus.
- “BtEvents” is a catch-all block for handling various external real-time interrupt sources. Currently it handles interrupts from the EC and RTC chips.
- “KeyScan” is the keyboard controller. It’s designed to scan a 9×10 keyboard matrix for key hits, using a slow external 32kHz clock source. By decoupling the keyboard scanner from the system core clock, the system can go to a lower power state while waiting for keyboard presses, extending the number of days that Precursor can go between charges.
- “BtPower” is a set of GPIOs dedicated specifically to managing power. It can turn the audio and discrete TRNG on and off, override the EC’s power control commands, activate boost mode for the USB type C port (allowing operation as a DFP or “host”), and engage the self-destruct mechanism.
- “JTAG” is a set of GPIOs looped back to the FPGA’s JTAG pins. These are used in combination with our eFuse API drivers to self-provision AES bitstream encryption fuses on the 7 Series FPGA.
- “XADC” is the interface for the 7-Series XADC block, which is a 12-bit, multi-channel ADC. This is primarily used for the self monitoring of system voltages. In the final production revision, at least one channel of the ADC will also be available as a configuration option on the GPIO internal header so that users have an easier path to integrating analog sensors into Precursor.
- “UART” is a simple 115200, 8-N-1 serial interface which is connected to the debug header for console I/O.
- “BtGpio” is a straight-forward digital I/O block for driving the pins on the GPIO internal header. Note that due to the nature of the FPGA’s implementation, it’s not possible to switch between a digital GPIO function and an analog GPIO function without updating the bitstream.
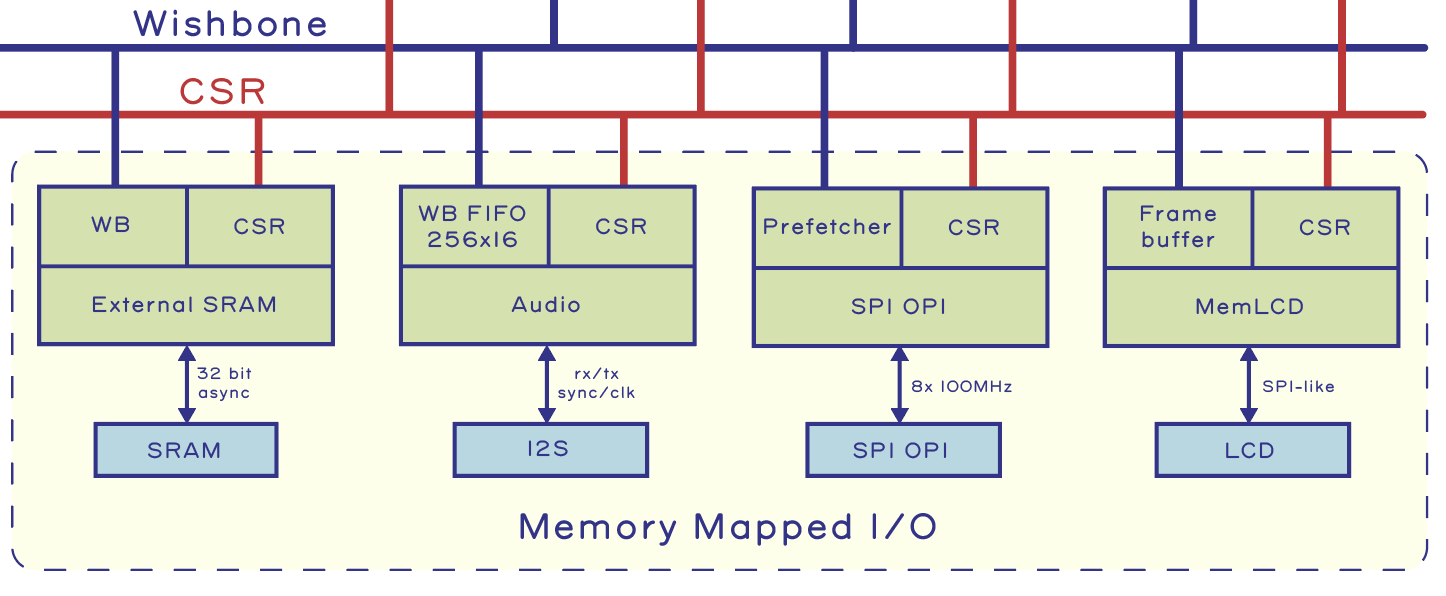
In addition to the CSR I/Os, a few I/O devices are memory-mapped for high performance:
- “External SRAM” is a 32-bit wide, asynchronous interface that memory-maps 16 MiB of external SRAM. The SRAM is battery-backed so that it can retain state while the SoC is powered off. The intention is to optimize power by reducing sleep/wake overhead. However, this also means that the self-destruct procedure must first clear sensitive data from SRAM before activating the final blow that knocks out the SoC, as the self-destruct circuitry is also powered by the SRAM’s backup power supply. The External SRAM block also has a CSR interface to read out the configuration mode of the SRAM.
- “Audio” is an I2S interface to an external audio CODEC. In addition to a CSR block that configures the I2S interface, it also includes a pair of 256×16 entry memory-mapped sample FIFOs.
- “SPI OPI” is a high-speed SPI-like interface to external FLASH storage that memory-maps 12 8MiB of non-volatile storage. The “O” in OPI stands for octal – it’s an 8-bit bus that runs at 100MHz DDR speeds. It also includes a pre-fetcher that can hold several cache line’s worth of code, optimizing the case of straight-line code execution. High performance on this bus is essential, since the intention is for the CPU to run most code as XIP out of FLASH. It also features a CSR interface to control operations like block erase and page programming.
- “MemLCD” is the frame buffer for the LCD. The Sharp Memory LCD contains its own internal memory, which allows it to retain an image even when the host is powered off. The MemLCD frame buffer is thus a cache for the LCD itself. It manages which lines of the LCD are dirty and will flush only the dirty lines to the LCD upon requests made via the CSR. This improves the perceived update rate of the LCD, which is limited to 10 Hz if the entire screen is being updated, but improves inversely proportional to the fraction of the screen that is static.
Cryptography Complex
All the features described thus far consume about 20% of the FPGA’s logic; the majority of the logic in Precursor’s FPGA is dedicated to the Cryptography Complex.
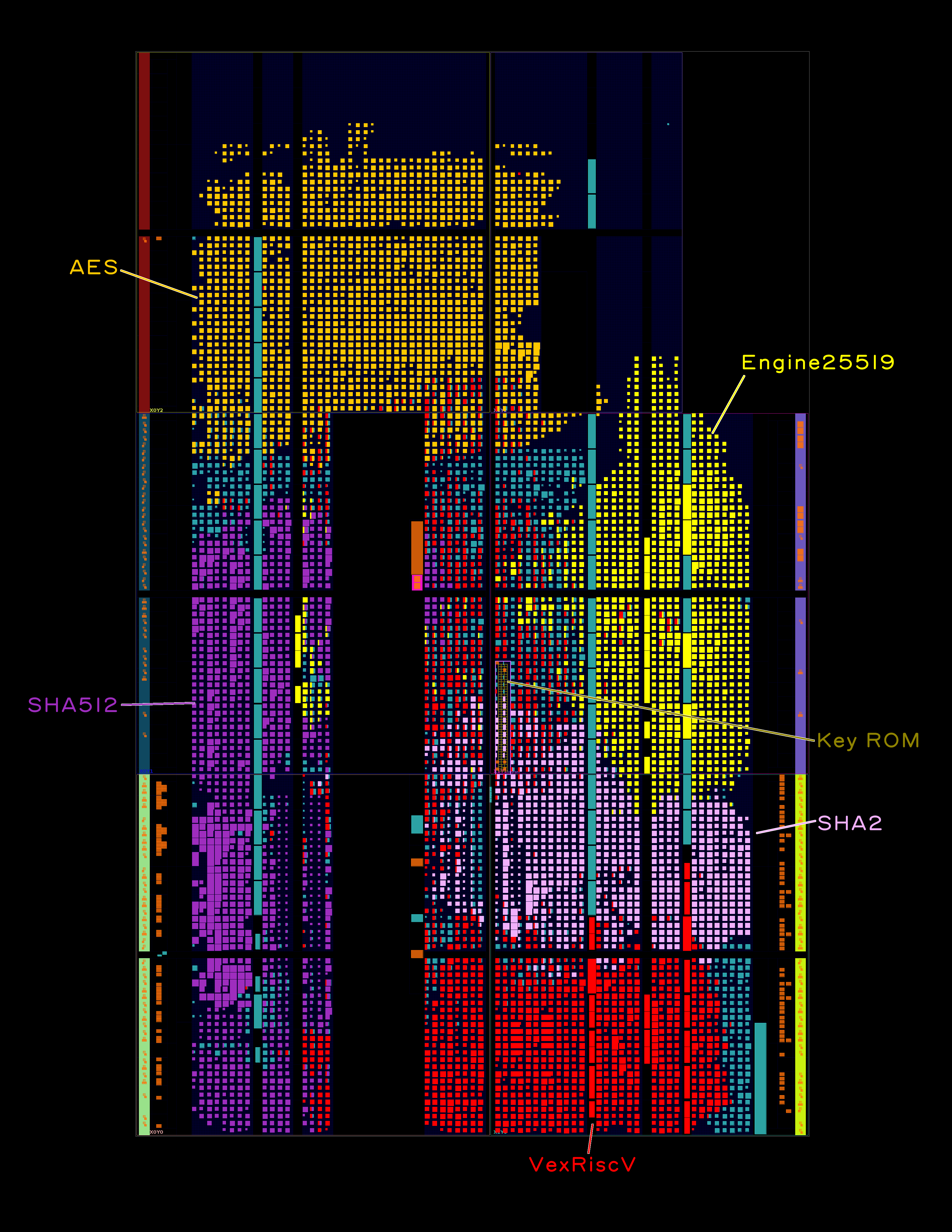
Above is an amoeba plot that visualizes the relative size of various functions within the Precursor SoC design. Some blocks, such as the semi-redundant SHA-512 and SHA-2 accelerators, are currently included simply because we could fit both of them in the FPGA, and not because we strictly needed both of them. Fortunately, removing the SHA-2 block is as easy as commenting out four lines of code, saving about 2800 SLICE LUTs or about 9% of the device’s resources. LiteX and the svd2rust scripts take care of everything else!
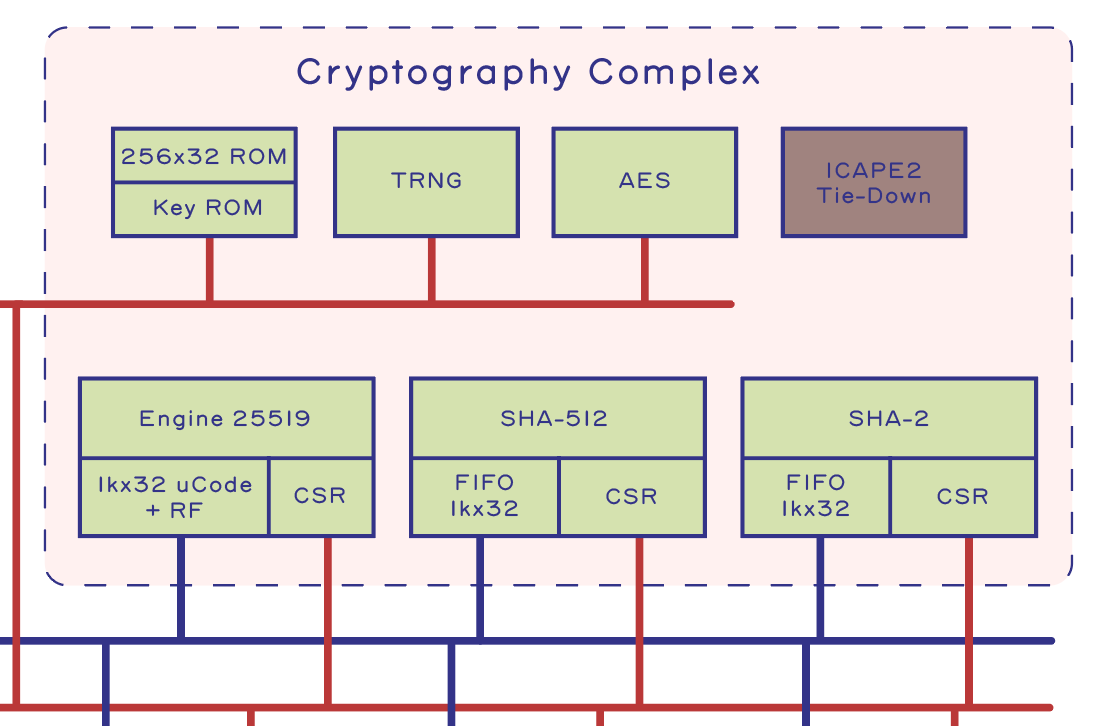
Here’s a quick run-down of the blocks inside the Cryptography Complex:
- “Engine25519” is an arithmetic accelerator for operations in the prime field 2^255-19. It’s a microcoded, 256-bit arithmetic engine capable of computing a 256-bit multiply plus normalization in about one microsecond, about a 30x speedup over running the equivalent code on the RISC-V CPU. It consumes a huge amount of resources, but was deemed essential because the Betrusted secure communications application is built around the Double-Ratchet Algorithm, which relies heavily on this type of math. The CI documentation is probably the best starting point to understand more about the Engine25519 implementation. The block is big enough that later on it will get an entire post dedicated to explaining its function.
- “SHA-512” and “SHA-2” are hardware-accelerated SHA hash blocks. They are derived from Google’s OpenTitan SystemVerilog source code. The SHA-2 block is directly from OpenTitan and included mostly because it was easy to integrate. The SHA-512 block is our own adaptation of the SHA-2 block. This is the historical reason for why we have both in the current build of Precursor, even though most applications will only need one hash or the other to be hardware accelerated.
- “AES” is an AES accelerator also lifted directly from the Google OpenTitan project. It is capable of doing AES 128, 192, and 256, and supports encryption and decryption in ECB, CBC, and CTR modes.
- “KeyROM” is a 256×32 ROM implemented using fixed-location LUTs in the FPGA. Since the ROM’s location is fixed, we can use PrjXray to determine the location of the KeyROM bits in the FPGA’s bitstream. This allows us to edit the key ROMs directly into the FPGA bitstream, thus enabling a transfer of trust from the low-level eFuse AES key into the higher-level functions of the Precursor SoC. We will discuss more about some important, recently-discovered vulerabilities in the FPGA eFuse AES key in a post coming soon.
- “TRNG” is an on-chip, ring oscillator-based TRNG. It uses multiple small rings to collect entropy which are then merged into a single large ring for final measurement. The construction and validation of Precursor’s TRNGs will also get their own post at some point down the road.
- “ICAPE2” is an explicit tie-down for an unused internal debug port in the FPGA fabric. ICAPE2 is Xilinx’s way of allowing an FPGA to introspect and access internal configuration state. We explicitly tie it down so that no other functions can try to claim it. Also, since the ICAPE2 is at a well-known location in the bitstream, it is possible to write a tool that does post-compilation inspection of the bitstream to verify that the ICAPE2 block is in fact deactivated.
Parting Thoughts
That’s it for our whistle-stop tour of the Precursor SoC! We’ve sculpted in the parts that are essential to functionality and security and hope the development community will add more. By commenting out a few lines of code, you can clear out unnecessary blocks and make space for your own creations. Precursor’s code base is entirely open and available for inspection – no hidden test logic or microcode blobs and no NDA required to trace an unambiguous, cycle-accurate path from the release of reset to the execution of the first instruction. This lack of “dark matter” and total transparency of design adds yet another argument in the evidence-based case to trust Precursor’s hardware with your private matters.
If you enjoyed this post, please check out Precursor’s campaign page for more details and project updates!