Akiba has new posts covering day 3 and day 4 of my “geek tour” course for MIT Media Lab students, held in Shenzhen, China. His website has been a little bogged down with traffic, so we’re thinking about migrating to a different server. Unfortunately, being inside the GFW (the Great Firewall of China) makes administering anything in the cloud a challenge.
Anyways, here’s the second installment of my four-part series titled “The Factory Floor”.
Process optimization: design for manufacturing and test jigs
It’s time to visit the topic of yield. This is a boring subject for many engineers, but for entrepreneurs, success or failure will be determined in part by achieving a reasonable yield. Unlike software, every copy of a physical good will have slight imperfections. Sometimes the imperfections will cancel out; and sometimes the imperfections gang up and degrade performance. As production volume ramps, these corner cases start adding up and a certain fraction of product ends up non-salable. In a robust design, the failing fraction may be so small that functional tests can be simplified, leading to further cost reductions. In contrast, designs sensitive to component tolerances will require extensive testing, and will suffer heavy yield losses. Reworking the defective units incurs extra labor and parts charges, ultimately leading to profit erosion.
Thus, a major challenge of moving from the engineering bench to mass production is re-designing to improve robustness in the face of normal manufacturing tolerances. This is called “design for manufacturing”, or DFM.
Examples of tolerances to consider during the design process include:
- Passive component tolerances (i.e. resistance +/- 5%, capacitance +80/-20%, etc.)
Spec sheet parameters that vary widely (such as hFE for bipolar transistors, Vt for FETs, Vf for LEDs). Always read the datasheet and keep an eye out for parameters that have a wide min-max spread. For example, the min-max on hFE for Fairchild’s 2N3904, ranges from 40 to 300, and the Vf on a superbright LED from Kingbright goes between 2 and 2.5V. - Voltage margins – particularly important for capacitors and input networks. As a rule of thumb, I try to spec capacitors with 2x headroom over nominal voltage, so I will try to use 10V caps for 5V rails and 6.3V caps for 3.3V rails. For example, many ceramic capacitor dielectrics reduce or derate their capacitance with increasing voltage. This means that ceramic capacitors in designs operating near their rated max voltage will see all the operating capacitances cornering toward the negative end of their tolerance range. Also, input networks – anything a user can plug something into – are subject to punishing ESD and other transient abuses, and special attention needs to be paid there to achieve the desired reliability.
- PCB trace widths and layer stack variations – impacts systems requiring matched impedance, or dealing with high currents.
- Mechanical tolerances – a case designed to fit a PCB with zero tolerance will result in the factory forcing PCBs into the case half the time, when either the PCB was cut a little large or the case came out a little small. This can lead to unintentional mechanical damage of the circuitry or the case.
- Cosmetic blemishes – any manufactured product is subject to small blemishes, such as dust trapped in plastics, small scratches, sink marks, and abrasions. It’s important to work out the acceptance criteria for such defects ahead of time – i.e., not more than two dot blemishes larger than 0.2mm per unit, no scratch longer than 0.3mm, etc. so that the process can be crafted to avoid such defects, as opposed to the more expensive alternative of just building units and throwing away the ones that don’t meet a set of criteria imposed late in the game. Of course, nothing comes for free – to do things on the cheap, avoid high-gloss finishes and consider using matte/textured finishes that naturally hide blemishes.
DFM Improves the Bottom Line
Let’s return to our LED blinker case study from part 1 of the series. Let’s say the prototype design calls for an array of three LEDs in parallel, each with its own current-set resistor. As noted above, Vf , the forward bias voltage of an LED at a given brightness, can vary by perhaps 20% between devices – in this case, from 2.0 to 2.5V. A design that uses resistive current limiting will amplify this variation. This is because an efficient circuit would drop a minority of the voltage across the current limiting resistor, leaving the parameter that sets the current – the voltage drop across the resistor – more sensitive to the variation in Vf. Since the brightness of an LED is proportional to the current flowing through the LED – not the voltage – the use of resistive current limiting to set LED brightness can lead to jarring inconsistencies in LED brightness uniformity.
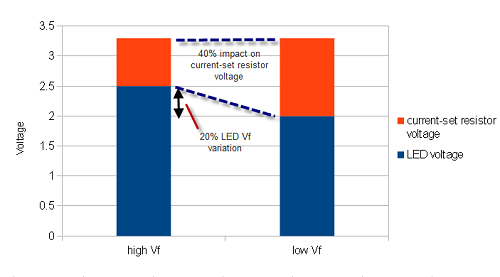
The above chart illustrates how a 20% LED Vf variation leads to a 40% change in the voltage across a current-set resistor for a fixed 3.3V supply, which will in turn lead to a 40% change in the current flowing through the LED, finally manifesting as a 40% change in perceived brightness.
Such a design may work well most the time – the problem is only pronounced when by chance a high Vf unit is paired with a low Vf unit. So for the one or two units prepared on the lab bench, things looked great.. However, a meaningful fraction of units may have brightness uniformities so bad there is choice but to reject the units. Given that most large hardware businesses have to survive on lean margins, losing even 10% of finished goods to defectivity is a terrible outcome.
One stop gap is to re-work the failed material. A factory can identify the LED that is too dim or too bright in an array, and replace it with a new one that may have a better chance of matching its cohorts. However, this rework drives up costs, and results in an unexpected and unpleasant invoice at the 11th hour of a manufacturing program. Naïve designers may be inclined to blame the factory for poor quality and argue over who should bear the cost, but it’s better to proactively avoid these kinds of problems by subjecting every design to a DFM check, and using a small pilot run to sanity-check yield before punching out a whole bunch of units.
The cost of yield fallout quantifies how much money to spend on extra circuitry to compensate for normal component variability. For example, a $10 COGS product that is yielding 80% good units has an effective cost per salable unit of $12.5 (calculated using COGS x total units built / yielded units). Therefore, increasing the COGS by $2.5 to improve yield to 100% breaks even, and spending $1 to improve yield to 99% improves the bottom line by $1.38.
In the case of the LED flasher, the dollar could be spent on a current-feedback boost regulator IC, allowing the LEDs to be stacked in series instead of parallel, so that each LED is guaranteed to have a consistent and identical amount of current flowing through them, thereby leading to greatly improved lighting uniformity. While the cost of the boost regulator is much greater than the penny spent on three current limiting LEDs, the improvement in manufacturing yield more than pays for the extra component costs.
Test for Success
The other often-neglected responsibility of a designer is the test program. A factory can only detect the problems they are instructed to look for. Therefore, every feature must be tested, no matter how trivial. For example, on a chumby device, every user-facing feature had an explicit factory test – LCD, touchscreen, audio, microphone, all the expansion ports (USB, audio), battery, buttons, knobs, etc. etc. Even the simplest buttons had to be tested. While it’s tempting to skip testing such simple components, I guarantee if it’s not tested, it will lead to returns.
And no, do not outsource the test program to the factory, even if they offer the service. First of all, the factory often doesn’t understand your design intent, so their test programs will either be inefficient, or they will test for the entirely wrong behavior. Also, factories have an incentive to pass as much material as possible, as quickly as possible, so factory-created test programs tend to be primitive and inadequate.
As a rule of thumb, for every product you make, you’re actually making two related products: one for the end user, and a test for the factory. In many ways, the test for the factory has to be as user-friendly and foolproof as the product itself – after all, tests are not run by electrical engineers. However, the related testing product will be much quicker and faster to build if adequate testability features are designed into the consumer product.
Here are some guidelines when it comes to designing a test program:
- Strive for 100% feature coverage. It’s often easy to overlook simple or secondary features – status LEDs, an internal voltage sensor, etc. As a sanity check, look at the device and list every way a consumer can interact with the device. Ask if the test program addresses every interaction surface, if even superficially – is every LED lit, every button pressed, every sensor stimulated and every memory device touched. If the product has a microcontroller, it’s also helpful to review which drivers are loaded to cross-check the test list. Finally, do a schematic review and look at every port and consider key internal nodes to monitor as part of the test.
- Minimize incremental setup effort. In other words, optimize the amount of time required to set up the test for each unit. This is often done through jigs that employ pogo pins or pre-aligned connector arrays. A test that requires an operator to manually probe test a dozen test points or insert a dozen connectors is time consuming and prone to manual error. Most factories in China can help design the jig for a nominal cost, but jig design is easier and more effective if the design is provisioned with adequate test points.
- Automate test execution in a linear execution flow. Ideally, a test just run with a single button press, and then produce a pass/fail result. In practice, there will always be stop points that require operator intervention. An example of too much intervention is requiring an operator to key in or select an SSID from a list every time during a test for wifi connectivity. Instead, fix the test target SSID and hard-code that value into the test script so that the connection cycle is automatic.
- Use icons and colors to communicate with operators, not text. Not every operator is guaranteed to be literate in a given language.
- Employ audit logs. Record test results correlated to device serial numbers by incorporating a barcode scanner into the test rig. An alternative is to create a “test coupon” or a locally stored audit log to prove which units have had the test run successfully. This gives some hints as to what went wrong when a consumer returns a failed product. It also gives a quick method to check that the test procedure is being executed on all products. After an eight-hour shift of running test, an operator is prone to making mistakes, such as putting a defective unit accidentally into the good units’ bin. Having a quick way to check that every product that ships has been subjected to and passed the full test can help identify and isolate such problems.
- Provide an easy update mechanism. Like any program, test programs also have bugs, and tests also need to evolve as the product has patches and upgrades applied . Thus it is imperative to have a mechanism to update and fix test programs without having to visit the factory every time in person. Many of my test fixtures have a mode where they can “phone home” via a VPN where I can then ssh into the jig itself to fix bugs: even my simplest jigs employ a linux laptop at its core.
The guidelines above are easy to implement if the product is designed with testability in mind. As most of the products I design run Linux, I leverage the processor inside the product itself to run the majority of the tests and manage the test UI. For products that lack user interaction surfaces, I will use an Android phone or a laptop connected via wifi or serial as the test UI.
Testing vs. Validation
Production tests are meant to check for assembly errors, not parametric variations or design issues. If a test is screening out devices because of normal parametric component variations, either buy better components, or re-do the design.
For consumer-grade products, there is no need to run a five minute comprehensive RAM test on every unit – in theory, a product should be designed well enough that if it’s all soldered together correctly, the RAM will do its job. A quick test to check that there are no stuck or open address pins is all that is really need. Name-brand chip vendors have typically very low defectivity rates, so we’re not validating the silicon; rather, we are validating the solder joints, connectors, and checking for missing or swapped components (note that if you buy clone chips or off-brand/remarked/partially tested devices to cut costs, it is advised to make a mini-validation program for those components).
To illustrate the point, let’s consider testing vs. validation for a switch.
A production test for a switch on a product may simply consist of asking the operator to hit the switch a few times and verify that the feel is right, and verify that electrical contact is made through a simple digital indicator.
A validation test for a switch may consist of taking a few devices, measuring contact resistance with a five-digit multimeter, subjecting them to 100% humidity at 40C overnight, and then putting the devices into an automated jig where the switches are cycled ten thousand times. Finally, the switches are re-measured with a five-digit multimeter and any degradation in close-state contact resistance is noted.
Clearly, this level of validation cannot be performed on every device manufactured. Rather, the validation program checks for performance of the switch over the expected lifetime of the product, and the test just makes sure the switch is put together right. Note that it is considered good practice to re-run validation tests on a couple randomly sampled units out of every several thousand units produced; there are formulas and tables to compute how much sampling is needed to achieve a certain level of quality.
So how much testing is enough testing? One threshold for testing can be derived through a cost argument. Every additional test run incurs test equipment costs, engineering costs, and the variable cost of the test time. As a result, testing is subject to diminishing returns: at some point, it’s cheaper just to take a product return than to test more. Naturally, the testing bar is much higher for medical or industrial grade equipment, as the liability associated with faulty equipment is also much higher. Likewise, a novelty product meant to be given away may get away with much less testing.
As a final thought, don’t dismiss the value of applying solid engineering to test jig design. I once had a problem once where a flat flex cable adapter with 50 pins had random cold solder joint failures. I asked the factory to build a test to validate the adapters. Their solution was to hang LEDs off of every pin of the adapter and put a test voltage into one side, and look for LEDs that don’t light up on the other side. The problem is that the cold solder joints weren’t simply open or closed – some were just high resistance. Enough current would flow to light an LED, yet enough resistance would be present to cause a fault in the design. After I noted this problem, the factory proposed buying 50 multimeters and hanging them off of every pin to check the resistance manually – an expensive and error-prone proposition. My response was to daisy-chain the connections across the adapter, and then use a single multimeter to check the net resistance of the daisy chain. Putting the connections in series checks all 50 connections with a single numeric measurement (as opposed to the subjective observation of an LED’s brightness). As one can see, even a test as simple as checking for cold solder joints on a cable adapter can have better or worse implementations. As ever more complicated components require ever more subtle tests, there is real value in applying solid engineering skills to crafting efficient yet foolproof tests.